
最近在打攻防时发现了一个隐写叫base64隐写,因为里面的东西涉及脚本和其他的我不知道的奇奇怪怪的知识,然后刁哥告诉我要做笔记,于是就直接搬了个大佬的笔记过来。
base64
BASE64 是一种编码方式,是一种可逆的编码方式.
编码后的数据是一个字符串,包含的字符为: A-Za-z0-9+/
共 64 个字符:26 + 26 + 10 + 1 + 1 = 64
其实是 65 个字符,= 是填充字符.
64 个字符需要 6 位二进制来表示,表示成数值为 0 ~ 63。
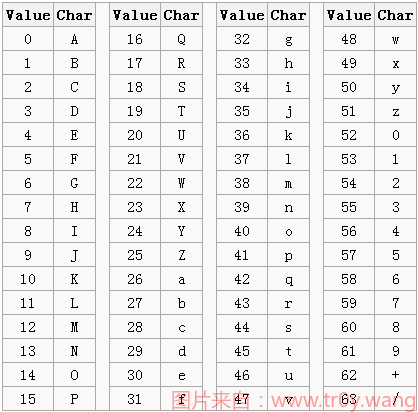
这样,长度为 3 个字节的数据经过 Base64 编码后就变为 4 个字节
编码
比如,字符串 Tr0 经过 Base64 编码后变为 VHIw

上面说的字符串长度为 3 个字节的数据位数是 8x3=24,可以精确地分成 6x4.
如果字节数不是 3 的倍数,则位数就不是 6 的倍数,那么就不能精确地划分成 6 位的块.
此时,需在原数据二进制值后面添加零,使其字节数是 6 的倍数.
然后,在编码后的字符串后面添加 1 个或 2 个等号,表示所添加的零值字节数.
比如,字符串 Tr0y 经过 Base64 编码后变为 VHIweQ==

橙色底纹就是添加的 0
这是 Base64 编码的方式
解码
解码就是编码的逆过程。
- 把 Base64 字符串去掉等号,转为二进制数(
VHIweQ==->VHIweQ->010101000111001000110000011110010000) - 从左到右,8 个位一组,多余位的扔掉,转为对应的 ASCII 码(
01010100 01110010 00110000 01111001 0000-> 扔掉最后 4 位 ->01010100 01110010 00110000 01111001->Tr0y)
隐写原理
注意红色的 0,我们在解码的时候将其丢弃了,所以这里的值不会影响解码. 所以我们可以在这进行隐写。为什么等号的那部分 0 不能用于隐写?因为修改那里的二进制值会导致等号数量变化,解码的第 1 步会受影响。自然也就破坏了源字符串。而红色部分的 0 是作为最后一个字符二进制的组成部分,还原时只用到了最后一个字符二进制的前部分,后面的部分就不会影响还原。
唯一的影响就是最后一个字符会变化。如下图

如果你直接解密VHIweQ==与VHIweR==‘,得到的结果都是’Tr0y‘。
当然,一行 base64 顶多能有 2 个等号,也就是有 2*2 位的可隐写位。所以我们得弄很多行,才能隐藏一个字符串,这也是为什么题目给了一大段 base64 的原因。接下来,把要隐藏的 flag 转为 8 位二进制,塞进去就行了。
加密
import base64
flag = 'Tr0y{Base64isF4n}' #flag
bin_str = ''.join([bin(ord(c)).replace('0b', '').zfill(8) for c in flag])
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('0.txt', 'rb') as f0, open('1.txt', 'wb') as f1: #'0.txt'是明文, '1.txt'用于存放隐写后的 base64
for line in f0.readlines():
rowstr = base64.b64encode(line.replace('\n', ''))
equalnum = rowstr.count('=')
if equalnum and len(bin_str):
offset = int('0b'+bin_str[:equalnum * 2], 2)
char = rowstr[len(rowstr) - equalnum - 1]
rowstr = rowstr.replace(char, base64chars[base64chars.index(char) + offset])
bin_str = bin_str[equalnum*2:]
f1.write(rowstr + '\n')
PYTHON解密
import base64
b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('stego.txt', 'rb') as f:
bin_str = ''
for line in f.readlines():
stegb64 = str(line, "utf-8").strip("\n")
rowb64 = str(base64.b64encode(base64.b64decode(stegb64)), "utf-8").strip("\n")
offset = abs(b64chars.index(stegb64.replace('=', '')[-1]) - b64chars.index(rowb64.replace('=', '')[-1]))
equalnum = stegb64.count('=') # no equalnum no offset
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
b = ''.join([chr(int(bin_str[i:i + 8], 2)) for i in range(0, len(bin_str), 8)]) # 8 位一组
data = ""
m = "flag{" + b + "}"
m = m.replace("\x00", "")
print(m)
使用这个脚本的时候要注意把对应的文件放在python文件下









