
rar文件数据块的组成
标记块:HEAD_TYPE=0x72
压缩文件头:HEAD_TYPE=0x73
文件头:HEAD_TYPE=0x74
旧风格的注释头:HEAD_TYPE=0x75
旧风格的用户身份信息:HEAD_TYPE=0x76
旧风格的子块:HEAD_TYPE=0x77
旧风格的恢复记录:HEAD_TYPE=0X78
旧风格的用户身份信息:HEAD_TYPE=0X79
子块:HEAD_TYPE=0x7A
最后的结束块:HEAD_TYPE=0x7B
隐写工具Steghide使用
今天刷题的时候遇到了这个工具,工具的作用是将隐藏信息从载体中分离出来。今天打了qnsctf上的一道题目,他把flag藏进了图片了,就需要用这个工具把他拉出来
steghide extract -sf test.jpg -p 123456
#-sf 参数
#test.jpg 图片名称
#-p 密码参数,后面空格跟密码,无密码可不加参数,回车就好将文件藏到载体中去
steghide embed -cf test.jpg -ef secret.txt -p 123456因为steghide本身不具备爆破密码的功能,这里我们需要借助shell脚本。就是说,如果不知道密码,就只能爆破。然后就是用脚i本shell,首先亮出shell脚本
#!/bin/bash
if [ $# -lt 2 ]; then
echo "Usage: $0 [steghide file] [dictionary file]"
exit 1
fi
file=$1
dict=$2
if [ ! -f $file ]; then
echo "Error: File not found: $file"
exit 1
fi
if [ ! -f $dict ]; then
echo "Error: Dictionary not found: $dict"
exit 1
fi
while read password; do
if steghide extract -sf $file -p $password &> /dev/null; then
echo "Password found: $password"
exit 0
else
echo "Trying: $password"
fi
done < $dict
echo "Password not found"
exit 1然后要将这个文本变成sh文件,后面就会开始报错,因为使用windows的记事本编辑的,会有一些字符会被替换,这时候就要用命令
vim exaple.sh
//进去后冒号打一个
:set ff=unix
:wq之后就可以用这个脚本了。然后我们还得编写密码集,不然拿什么爆破,这玩意儿还得手搓,真恶心。
crunch <min-len> <max-len> [<charset string>] [options]
min-len crunch要开始的最小长度字符串,max-len crunch要开始的最大长度字符串,charset string 是指定设置的字符集,否则将使用缺省的字符集设置,缺省的设置为小写字符集,大写字符集,数字和特殊字符(符号),options则是后面可以追加的一些参数。
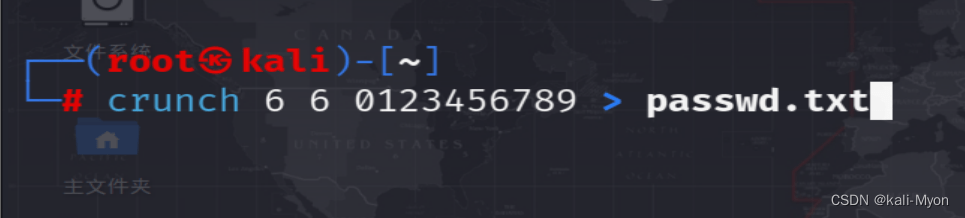
然后就是运行就可以了
./脚本名 要爆破的图片名 密码字典
提瓦特现行文字加密

USB流量分析之鼠标流量和键盘流量
今天做到一题USB流量分析,首先做题顺序是寻找HID数据包,因为USB HID是人机接口设备的数据,所以需要从这上面去寻找突破口。
用命令提取鼠标流量
tshark -r usb.pcapng -T fields -e usbhid.data > usbdata.txt音频隐写
MP3隐写
如果音频文件带有key值的话,可以尝试MP3隐写。
使用MP3Stego工具进行解密
命令为
Decode.exe -P password -X 文件路径MP3文件文件头:ID3;49 44 33
wav文件头:52494646E6AD250357415645666D7420
然后还看到了一种带有key的音频隐写破解工具,但是我没有试过,silenteye、deepsound,等下次再研究吧。
拨号隐写工具使用(DTMF)
dtmf-decoder-master
您必须提供一个 wav 文件(例如,您可以尝试转换它)。
ffmpeg -i audio.mp3 audio.wav
无噪音文件提取
dtmf perfect-example.wav有噪音文件提取
dtmf not-perfect-example.wavdtmf -v not-perfect-example.wav //根据不同的秒数之间列出可能的所有数字文件头总结
PNG (png),文件头:89504E47
GIF (gif),文件头:47494638
TIFF (tif),文件头:49492A00
Windows Bitmap (bmp),文件头:424DC001
CAD (dwg),文件头:41433130
Adobe Photoshop (psd),文件头:38425053
Rich Text Format (rtf),文件头:7B5C727466
XML (xml),文件头:3C3F786D6C
HTML (html),文件头:68746D6C3E
Email thorough only,文件头:44656C69766572792D646174653A
Outlook Express (dbx),文件头:CFAD12FEC5FD746F
Outlook (pst),文件头:2142444E
旧版office MS Word/Excel (xls.or.doc or.ppt),文件头:D0CF11E0
MS Access (mdb),文件头:5374616E64617264204A
WordPerfect (wpd),文件头:FF575043
Adobe Acrobat (pdf),文件头:255044462D312E
Quicken (qdf),文件头:AC9EBD8F
ZIP Archive (zip),文件头:504B0304
RAR Archive (rar),文件头:52617221
Wave (wav),文件头:57415645
JPEG (jpg),文件头:FFD8FFE1
一些冷门的文件格式
webp:一种图片格式
bpg:也是一种图片格式
psd:图片格式,通常是ps保存下来的文件
bpgview工具使用
bpg作为一种冷门的图片格式,正常情况下是打不开的。所以要用到工具bpgview
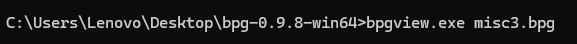
正常的使用方式就是,把图片放置于文件目录下,然后运行bpgview.exe程序+图片名称就可以了
PNGdebuger使用
进入debug文件夹下cmd
然后
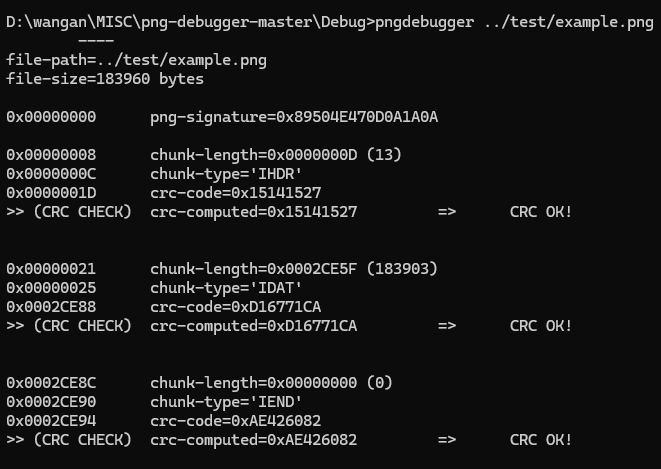
路径随意吧,../就是为了返回上一级目录
pngdebugger ../test/example.png还有查看更详细的命令的,比如宽高
pngdebugger --verbose ../test/example.pngzsteg工具使用
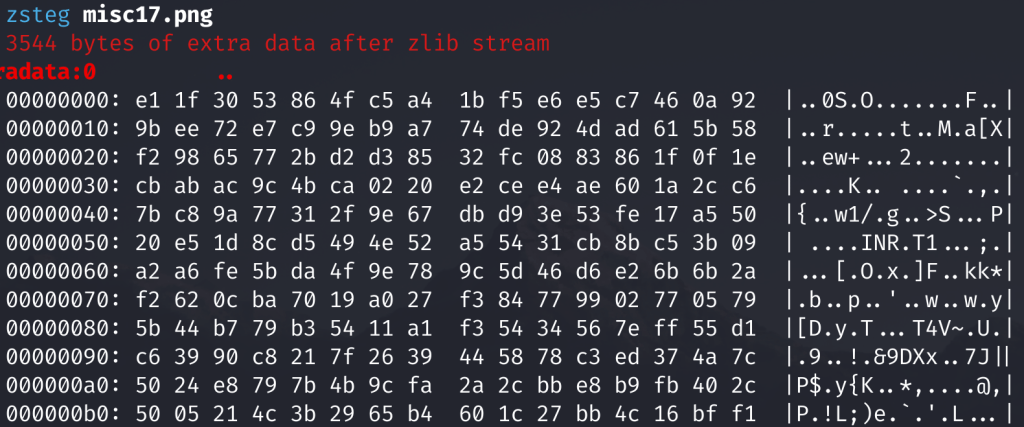
#-b的位数是从1开始的
zsteg zlib.bmp -b 1 -o xy -v //检测zlibzsteg -e b8,a,lsb,xy 文件.png -> out.png //提取该通道图片
通道就是数据左上角有对应的数据
我做的这一题还得binwalk一手,先记录下来。
猫脸变换
import os
import cv2
import argparse
import numpy as np
from PIL import Image
parser = argparse.ArgumentParser()
parser.add_argument('-t', type=str, default=None, required=True, choices=["encode", "decode"],
help='encode | decode')
parser.add_argument('-f', type=str, default=None, required=True,
help='输入文件名称')
parser.add_argument('-n', type=int, default=1, required=False,
help='输入参数n')
parser.add_argument('-a', type=int, default=None, required=True,
help='输入参数a')
parser.add_argument('-b', type=int, default=None, required=True,
help='输入参数b')
args = parser.parse_args()
def arnold(img, a, b):
new_img = np.zeros((r, c, 3), np.uint8)
for _ in range(n):
for i in range(r):
for j in range(c):
x = (i + b * j) % r
y = (a * i + (a * b + 1) * j) % c
new_img[x, y] = img[i, j]
img = np.copy(new_img)
return new_img
def dearnold(img, n, a, b):
new_img = np.zeros((r, c, 3), np.uint8)
for _ in range(n):
for i in range(r):
for j in range(c):
x = ((a * b + 1) * i - b * j) % r
y = (-a * i + j) % c
new_img[x, y] = img[i, j]
img = np.copy(new_img)
return new_img
if __name__ == '__main__':
img_path = os.path.abspath(args.f)
file_name = os.path.splitext(img_path)[0].split("\\")[-1]
img = np.array(Image.open(img_path), np.uint8)[:,:,::-1]
r, c = img.shape[:2]
n, a, b = args.n, args.a, args.b
if args.t == "encode":
new_img = arnold(img, a, b)
elif args.t == "decode":
new_img = dearnold(img, n, a, b)
else:
print("[-] 图片宽高不一致, 无法进行猫脸变化!")
exit()
cv2.imwrite(f"./{file_name}_{n}_{a}_{b}.png", new_img)
Exiftool工具使用
没有什么特别的
就是个查看exif的工具,exif说的简单点就是数码相机拍的图片信息
Jiayu工具箱使用
进入文件

然后
java -jar JiayuTools.jar比较吸引我的是这个键盘鼠标流量一把梭
注意路径,不要引号和盘符
MD5生成脚本
import hashlib
res = ''
for i in range(10000):
res += hashlib.md5(str(i).encode()).hexdigest() + '\n'
with open("dic.txt",'w') as f:
f.write(res)SHA-256生成脚本
import hashlib
# 创建一个数字列表
numbers = [str(i) for i in range(10)]
# 打印每个数字及其SHA-256值
for number in numbers:
sha256_hash = hashlib.sha256(number.encode()).hexdigest()
print(f"数字: {number}, SHA-256: {sha256_hash}")
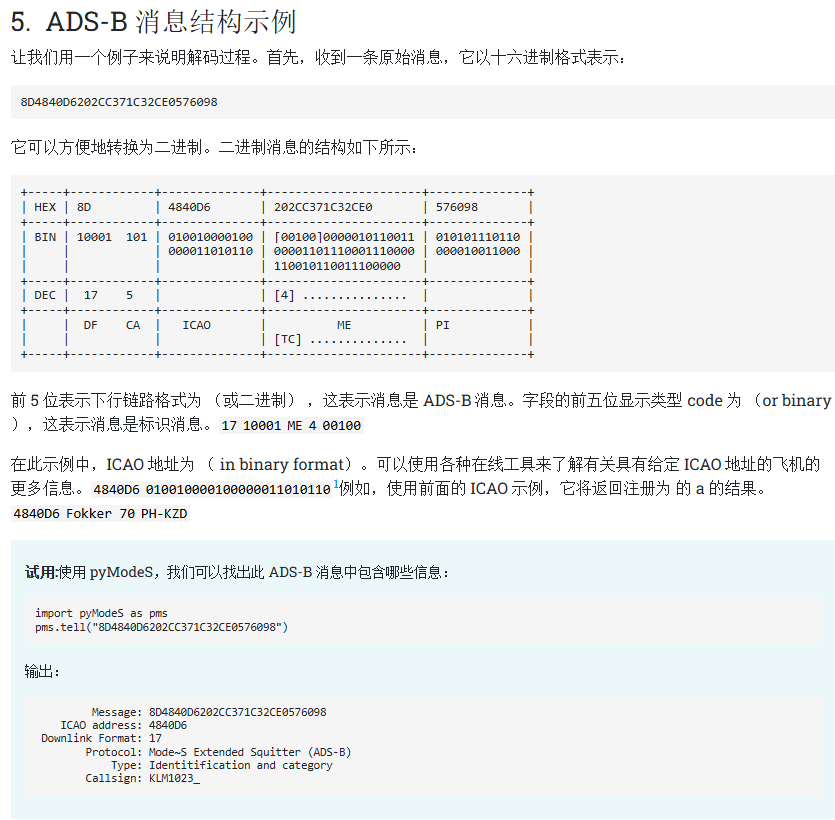
流量分析之ADS-B 基础知识
ADS-B 是 Automatic Dependent Surveillance-Broadcast 的缩写。它是一个基于卫星的监控系统。位置、速度和标识等参数通过 S 模式 Extended Squitter (1090 MHz) 传输。如今,大多数飞机不断广播 ADS-B 消息。从 2020 年开始,欧洲和美国的民用航空飞机必须符合 ADS-B 标准。不符合 ADS-B 要求的旧飞机需要在几年内进行改装或逐步淘汰。
压缩包套娃一把梭
import io
import zipfile
with open("ez_zip的附件.zip", "rb") as f:
data = f.read()
info = "taptap"
while True:
with zipfile.ZipFile(io.BytesIO(data), "r") as zf:
all_files_processed = True
for i in zf.filelist:
fileName = i.filename.encode("cp437").decode("gbk")
if zipfile.is_zipfile(io.BytesIO(zf.read(i.filename))):
print(fileName)
data = zf.read(i.filename)
all_files_processed = False
info += f" {fileName.replace('.zip', '')}"
else:
print(fileName)
with open(fileName, "wb") as f:
f.write(zf.read(i.filename))
if all_files_processed:
break
print(info)pcapng文件转换脚本
def hex_to_pcapng(hex_string, output_file):
# 将十六进制字符串转换为字节数据
byte_data = bytes.fromhex(hex_string)
# 将字节数据写入文件
with open(output_file, 'wb') as f:
f.write(byte_data)
def clean_hex_string(hex_string):
# 清理输入,去掉任何非十六进制字符,并确保长度为偶数
cleaned_hex = ''.join(filter(lambda x: x in '0123456789abcdefABCDEF', hex_string))
# 如果长度是奇数,则移除最后一个字符以确保长度为偶数
if len(cleaned_hex) % 2 != 0:
print("警告:十六进制字符串长度为奇数,已自动修正。")
cleaned_hex = cleaned_hex[:-1]
return cleaned_hex
if __name__ == "__main__":
# 读取十六进制字符串(假设从文件中读取)
input_file = r"C:\\Users\\Lenovo\\Desktop\\Checkin\\FLag.txt"
with open(input_file, 'r') as f:
hex_string = f.read().strip()
# 检查文件是否以0d0a开头并去除之
if hex_string.startswith('0d0a'):
hex_string = hex_string[4:]
# 打印出 hex string 以供调试
print(f"原始十六进制字符串:{hex_string}")
# 清理输入
hex_string = clean_hex_string(hex_string)
# 写入pcapng文件
output_filename = r"C:\\Users\\Lenovo\\Desktop\\Checkin\\2.pcapng"
hex_to_pcapng(hex_string, output_filename)
print(f"已成功转换为 {output_filename}")gif提取帧间隔
linux命令:
identify -format "%T " kk.gif > flag.txt
遇到gif文件的第二种类型问题,通过提取帧间隔然后转换成二进制进行ascii解码
Modbus协议提取脚本
import pyshark
captures = pyshark.FileCapture("flag.pcapng", tshark_path="F:\\Wireshark\\tshark.exe")
func_codes = {}
idx = 1
flag = False
for c in captures:
for pkt in c:
if pkt.layer_name == "modbus":
func_code = int(pkt.func_code)
if func_code == 16:
if flag:
flag = False
continue
payload = str(c["TCP"].payload).split(":")[-1]
payload = '0x' + payload
print(chr(int(payload, 16)), end="")
flag = True
idx += 1流量分析之sql流量

一般会出这种盲注,然后盲注的话,就只要选择每个字符的最大的那一位然后进行字符串转换就可以,但是比较麻烦的是要一个一个去找,然后提取出flag,太慢了,于是就可以使用kali里头的命令快速拉取flag
tcpdump -r timu.pcapng -A|grep "You are in..........." -B50|grep "substr((select%20flag%20from%20t)," |grep "192.168.246.23" -v | cut -d '=' -f 3 |cut -d '-' -f 1 > flag
awk '{printf "%c", $0}' flag
-A以ascii形式读取文件,然后grep取截取信息,you are in是活的flag时候的回显,这个自己去灵活改变就好,然后就是截取sql诸如命令之后的=号和-号之间的数字,最后以字符串的形式输出就行
NTFS隐写
ntfs隐写就是再一个文件里头再写入一个文件,然后写入的这个文件是隐藏起来的
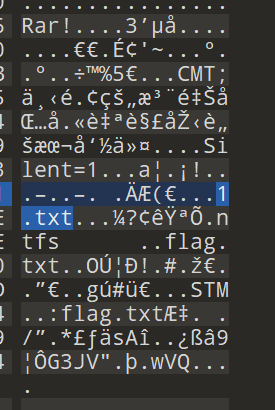
通过010可以可能到这里头有两个文件,然后通过cmd指令
notrepad 1.txt:flag.txt就可以将里面的隐藏文件扒出来










